
Jak wygląda proces tłumaczenia oprogramowania?
No… to tłumaczymy, czyli projekt lokalizacyjny oprogramowania.
Jak przetłumaczyć dokument? Osobom niezaznajomionym z branżą tłumaczeniową i narzędziami w niej używanymi wydawać by się mogło, że to banalnie proste: trzeba go otworzyć w edytorze, na przykład nieśmiertelnym Wordzie, i zastąpić zdania źródłowe (angielskie, niemieckie czy jeszcze inne) zdaniami w naszym języku. Jeśli zdania są złożone, to można po kawałku. Jak przetłumaczyć książkę? Zapewne tak samo, tylko dłużej. Jak przetłumaczyć stronę WWW? To trochę trudniejsze, ale pewnie da się ją zapisać do pliku, a potem otworzyć w… yyy, Wordzie i… No dobrze, tymczasowo uznajmy, że to prawda. Prawda z gatunku tych, które podaje oficjalna telewizja w kraju rządzonym przez dyktatora. W każdym razie można przyjąć, że w przypadku dokumentów takie rozwiązanie jest możliwe. Zapewne są jeszcze tłumacze, którzy zamknięci w schronach przeciwatomowych w niebiesko-żółtych wdziankach tak właśnie pracują, czekając, aż otworzą się drzwi krypty i postnuklearny świat stanie otworem. Nawet oni jednak zaczną drapać się po głowie, gdy przyjdzie przetłumaczyć coś innego. Coś działającego. Program. Aplikację. A skoro o nich mowa, to trzeba użyć magicznego słowa „interfejs”. Interfejsem jest wszystko to, co program wyświetla użytkownikowi. Grafiki, teksty, filmy, komunikaty. Jego częścią są nawet elementy komunikacji głosowej. Bo interfejs (ang. inter+face, co w wolnym tłumaczeniu oznacza miejsce interakcji dwóch systemów — tutaj człowieka i oprogramowania), jak sama nazwa wskazuje, ma być pomostem między bezdusznym i zerojedynkowym światem programu a skomplikowanym wewnętrznie użytkownikiem. Choć interfejs jest pośrednikiem, to równocześnie stanowi integralną część oprogramowania. A jak przetłumaczyć ten diabelny interfejs? Gmerając w urządzeniu zamontowanym na przedramieniu, wspomniany już uciekinier z krypty tłumaczeniowej od razu zauważy, że interfejs składa się z jakichś tekstów, które można by pewnie wrzucić do znanego mu monochromatycznego edytora tekstu, gdyby ktoś tylko odrobinę podpowiedział, jak się do nich dobrać. Samo wydłubanie zasobów bowiem nie wystarczy — trzeba je umiejętnie wstawić z powrotem. I to w taki sposób, aby oprogramowanie sterujące pracą reaktora elektrowni atomowej nie zrobiło czegoś głupiego. A jeśli program zrobi głupstwo tylko po przełączeniu interfejsu na inny język, to pewnie ktoś będzie gotów posądzić tłumacza o sabotaż. Co to właściwie jest ta lokalizacja oprogramowania? Aby odpowiedzieć na to pytanie, warto się przyjrzeć, jak oprogramowanie jest zrobione. Mimo ładnej nazwy pozbawione jest mistycznej oprawy i stanowi jedynie ciąg instrukcji zapisanych tak, aby maszyna je zrozumiała. Zwykle instrukcje te każą maszynie (na przykład komputerowi stojącemu na naszym biurku) wykonać serię obliczeń, które — jak dobrze pójdzie — będą skutkować tym, czego sobie projektant aplikacji zażyczył. Tu pojawia się pierwsza prawdziwa zbieżność między światem tłumaczy i światem programistów. Programista bowiem tłumaczy projekt aplikacji (lub wręcz algorytm — projekt rozpisany na kolejne kroki do wykonania) na język, który będzie zrozumiały dla maszyny. Dziś najczęściej robi to nie wprost, lecz używa tak zwanych języków wysokiego poziomu, w których może mniej lub bardziej zrozumiale dla człowieka zapisać „wczytaj dwie liczby z klawiatury, dodaj zmienną x do y” itd. Taki zapis to kod źródłowy. Nie widać w nim fizycznych odwołań do rejestrów procesora i znajdujących się w nich zer i jedynek. A te liczby — kod maszynowy — to jedyna forma zapisu, jaką zrozumie procesor. Jeśli człowiek potrzebuje spojrzeć osobiście na kod maszynowy, ułatwia to sobie, przedstawiając go w postaci mnemoników tak zwanego języka niskiego poziomu (asemblera). Kod źródłowy i kod maszynowy to dwa różne zapisy, zatem potrzebny jest mechanizm, który przełoży jeden język (tak, tak!) na drugi. Brzmi znajomo? Bezpośrednim przetłumaczeniem instrukcji zajmuje się tu jednak nie człowiek, a specjalny program — kompilator. Cybernetyczny tłumacz, który tłumaczy w miarę cywilizowany zapis ułożony przez programistę na kod maszynowy. Przykładowy kod źródłowy wygląda tak[1]:
extern *; writel("Podaj liczbe"); new var = readl(); if(var>5)writel("tak"); else writel("nie");
Odpowiadający mu kod maszynowy (jak wspomnieliśmy, przedstawiamy go za pomocą mnemoników asemblera) wygląda tak:
0 PUSH 35 7 PUSH 0 14 LABEL 17 CALL writel 27 CALL readl 36 PUSH Podaj liczbe
(I tak dalej).
Z perspektywy lokalizacji oprogramowania interesuje nas głównie kwestia wyłuskania części danych, czyli w uproszczeniu — tekstu, który ma zostać przetłumaczony. W prawidłowo skonstruowanej aplikacji dane podlegające lokalizacji będą wyraźnie oddzielone od kodu źródłowego aplikacji. Takie zasoby można sobie wyobrazić jako schowek w samochodzie. Nie musimy się znać na serwisowaniu silnika, żeby wyjąć ze schowka książkę z instrukcją obsługi i włożyć w jej miejsce taką samą, tyle że już przetłumaczoną. Samochód nawet tego nie zauważy. Oczywiście świat, a w szczególności świat lokalizacji oprogramowania, daleki jest od doskonałości, zatem znamy mnóstwo przykładów sytuacji, w których nie wszystko poszło tak gładko. Warto jednak zdefiniować pewien proces wzorcowy:
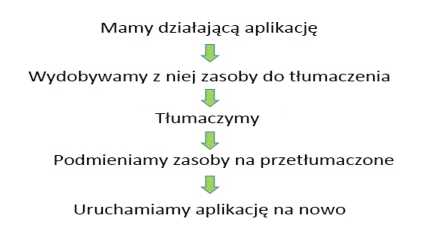 No i tak to w zasadzie działa, tylko na koniec dochodzi jeszcze testowanie wersji zlokalizowanej. Etap tak ważny, że będzie o nim osobny rozdział.
Niejaka trudność pojawia się na etapie wydobywania i potem podmieniania. Istnieją wprawdzie aplikacje, w których od razu przewidziano lokalizowanie interfejsu i przygotowano go w łatwych do podmiany plikach, a nawet dostarczono do tego (lepsze lub gorsze) narzędzie. Wcale nie jest to jednak normą. Możliwości są ogromne — od tekstów interfejsu zaszytych w binarnym kodzie programu (w dalszej części rozdziału pokażemy, że i do tego można się czasem dobrać) po materiał, który co prawda daje się wydobyć z programu do plików zewnętrznych i po przetłumaczeniu z powrotem umieścić w programie, jednak zawartość plików przypomina sushi po góralsku, czyli pstrąga porąbanego ciupagą. Gdzieś pośrodku mieszczą się rozsądnie przygotowane zasoby, które daje się bez problemu zrozumieć.
Drugim — po dobraniu się do zasobów interfejsu — wyzwaniem przy lokalizacji oprogramowania jest cykl jego produkcji. Pod tą nieco nadętą nazwą kryje się fakt, że producent programu chce go zwykle zlokalizować za jednym przysiadem — to znaczy tak, żeby oprócz wersji angielskiej sprzedać na przykład polską, a nie taką, w której przetłumaczono na razie jedno menu i trzy ekrany. Co nie znaczy, że tłumacze nie pracują czasem na takim właśnie wycinku materiału, ale do tego dojdziemy przy metodyce Agile. Na razie wprowadźmy pojęcie projekt lokalizacyjny. Jest to zakres prac lokalizacyjnych, dzięki któremu aplikacja zostanie zlokalizowana w całości i zgodnie z wymaganiami technicznymi danego języka.
Etap „tłumaczymy” z poprzedniego schematu można rozpisać tak:
No i tak to w zasadzie działa, tylko na koniec dochodzi jeszcze testowanie wersji zlokalizowanej. Etap tak ważny, że będzie o nim osobny rozdział.
Niejaka trudność pojawia się na etapie wydobywania i potem podmieniania. Istnieją wprawdzie aplikacje, w których od razu przewidziano lokalizowanie interfejsu i przygotowano go w łatwych do podmiany plikach, a nawet dostarczono do tego (lepsze lub gorsze) narzędzie. Wcale nie jest to jednak normą. Możliwości są ogromne — od tekstów interfejsu zaszytych w binarnym kodzie programu (w dalszej części rozdziału pokażemy, że i do tego można się czasem dobrać) po materiał, który co prawda daje się wydobyć z programu do plików zewnętrznych i po przetłumaczeniu z powrotem umieścić w programie, jednak zawartość plików przypomina sushi po góralsku, czyli pstrąga porąbanego ciupagą. Gdzieś pośrodku mieszczą się rozsądnie przygotowane zasoby, które daje się bez problemu zrozumieć.
Drugim — po dobraniu się do zasobów interfejsu — wyzwaniem przy lokalizacji oprogramowania jest cykl jego produkcji. Pod tą nieco nadętą nazwą kryje się fakt, że producent programu chce go zwykle zlokalizować za jednym przysiadem — to znaczy tak, żeby oprócz wersji angielskiej sprzedać na przykład polską, a nie taką, w której przetłumaczono na razie jedno menu i trzy ekrany. Co nie znaczy, że tłumacze nie pracują czasem na takim właśnie wycinku materiału, ale do tego dojdziemy przy metodyce Agile. Na razie wprowadźmy pojęcie projekt lokalizacyjny. Jest to zakres prac lokalizacyjnych, dzięki któremu aplikacja zostanie zlokalizowana w całości i zgodnie z wymaganiami technicznymi danego języka.
Etap „tłumaczymy” z poprzedniego schematu można rozpisać tak:
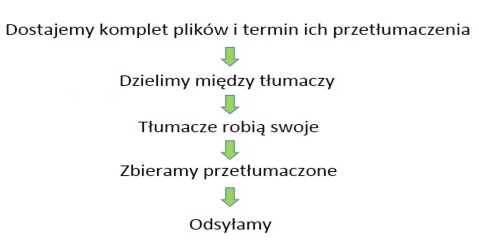 Tym, co musi wydarzyć się przed i po, zajmują się działy lokalizacji oprogramowania.
Przywołana wcześniej „titanicowa” góra lodowa pokazała nam, że część danych jest celowo ukryta. Co jednak z tymi danymi, których wydłubanie ma sens i może być dla nas pożyteczne? I jak to się łączy z perspektywą firmy zajmującej się tłumaczeniami? Przede wszystkim warto sobie uświadomić, że zwykle widzimy tylko fragment większego łańcucha powiązań. Tłumaczenie egzystuje dziś jako wypadkowa wielu innych procesów. Każda organizacja układa swoje wewnętrzne procesy nieco inaczej (rysunek 2.1). Ogólnie jednak kilka podstawowych procesów powtarza się w niemal każdej większej organizacji.
Tym, co musi wydarzyć się przed i po, zajmują się działy lokalizacji oprogramowania.
Przywołana wcześniej „titanicowa” góra lodowa pokazała nam, że część danych jest celowo ukryta. Co jednak z tymi danymi, których wydłubanie ma sens i może być dla nas pożyteczne? I jak to się łączy z perspektywą firmy zajmującej się tłumaczeniami? Przede wszystkim warto sobie uświadomić, że zwykle widzimy tylko fragment większego łańcucha powiązań. Tłumaczenie egzystuje dziś jako wypadkowa wielu innych procesów. Każda organizacja układa swoje wewnętrzne procesy nieco inaczej (rysunek 2.1). Ogólnie jednak kilka podstawowych procesów powtarza się w niemal każdej większej organizacji.
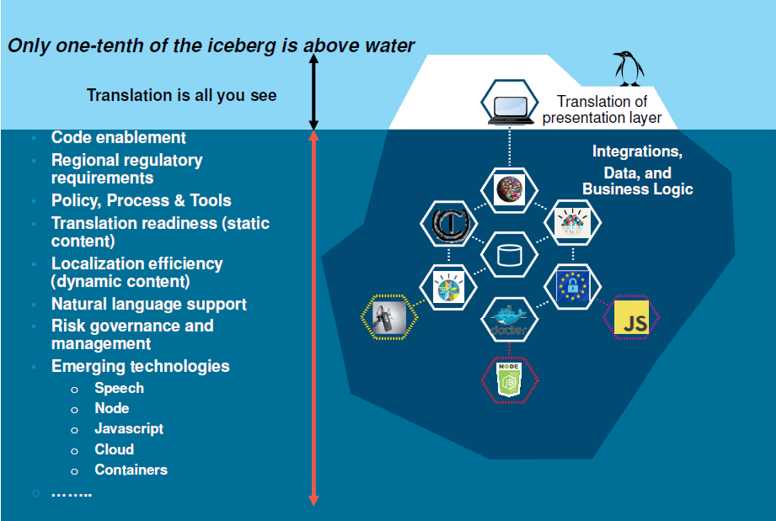 Rysunek 2.1. Taniec pingwina na tłumaczeniowej górze lodowej[2]
Rysunek 2.1. Taniec pingwina na tłumaczeniowej górze lodowej[2]
Z perspektywy branży tłumaczeniowej widać oczywiście samo tłumaczenie i zasoby, które zostały wyodrębnione i wysłane do dalszej pracy. Nie widać wszystkiego tego, co dzieje się z takimi zasobami przed procesem tłumaczenia i po nim. Producenci oprogramowania często wdrażają swoje systemy w różnych środowiskach. Tam zatem pojawiać się będą wszelkie wyzwania związane z integrowaniem oprogramowania, analizą procesów biznesowych organizacji i te wszystkie inne poważne słowa, dzięki którym można później wystawiać faktury z wieloma zerami, poważnie kiwając przy tym głową. Programista zaś musi sobie poradzić z długą listą wymogów klienta (na przykład organizacji, która oczekuje dostosowania produktu do potrzeb wybranych rynków) i ogólnych wymogów lokalizacyjnych, które przybierają formę reguł internacjonalizacji — o nich będzie mowa kilka opakowań pizzy później. Tu warto jeszcze wspomnieć o kolejnej niewidocznej warstwie, a więc obsłudze technologii. Branża tłumaczeniowa będzie traktować te zagadnienia jako rzecz naturalną i oczywistą, ale wszystkie tłumaczone zasoby mogą pochodzić z bardzo różnych modułów oprogramowania. Mogą dotyczyć sprzętu, który dopiero powstaje, ale mogą też dotyczyć programów i technologii, które mają swoje ograniczenia. I te ograniczenia będą miały konsekwencje dotyczące wszystkiego, co później trafia do lokalizacji. Może się na przykład okazać, że wyświetlacz urządzenia pozwala skorzystać z zaledwie 20 znaków w wierszu. Może się okazać, że sterownik danego urządzenia nie obsługuje jakiejś strony kodowej czy rodziny fontów. I tak dalej. To wszystko jednak znajduje się często pod powierzchnią wody i czyha na niewinnego tłumacza w formie kolejnej góry lodowej. Lub góry czegoś zupełnie innego. Klasyczna metodyka (aktualnie na wymarciu) dzieli etap tłumaczenia na serię mniejszych kroków:
- Przygotowanie materiału do tłumaczenia przez klienta i jego dostarczenie.
- Tłumaczenie.
- Korekta, redakcja, weryfikacja.
- Wyrywkowe przejrzenie materiału na zasadzie ostatniego rzutu okiem.
- Przetworzenie materiału do wymaganego formatu.
- Ocena jakości u zleceniodawcy.
- Wprowadzenie uwag od zleceniodawcy.
- Wygenerowanie zlokalizowanego materiału u klienta.
- Testowanie lokalizacji.
Rzeczywistość, z jaką tłumacz spotyka się w większości firm lokalizacyjnych, na pewno będzie zawierać jakiś podzbiór tych punktów.
Wszystko płynie niczym plik banknotów, który wywiany przez wiatr z naszego portfela wpadł do rzeki i leniwie zmierza w stronę lepszego domu (choćby królestwa Aquamana). Również praca tłumacza nie tkwi w miejscu i jeśli można coś powiedzieć o typowym warsztacie tłumacza, to to, że niemal każdy tłumacz każdego roku otrzymuje i odsyła tysiące dokumentów. Większość z nich na szczęście nie trafia do zbiorników wodnych, ale i tak stanowi element codziennego procesu tłumaczeniowego, który zaczyna się gdzieś w okolicach systemów zarządzania treścią w firmie zleceniodawcy. W dalszej drodze dokument zwykle przewija się przez biurko kierownika projektów agencji tłumaczeniowej, aby trafić przed oczy kota i CAT-a tłumacza, a następnie zatoczyć koło i poprzez agencję wrócić do klienta po dodatkowej weryfikacji. To oczywiście jeden z wielu możliwych scenariuszy, który pokazuje jedynie, że projekt lokalizacyjny to zamknięty cykl powiązań. Po drodze jednak oprócz samego przekazywania dokumentów funkcjonuje sporo procesów pobocznych — w szczególności procesów skupionych wokół zasilania przeróżnych baz danych i ewidencji zleceń (rysunek 2.2).
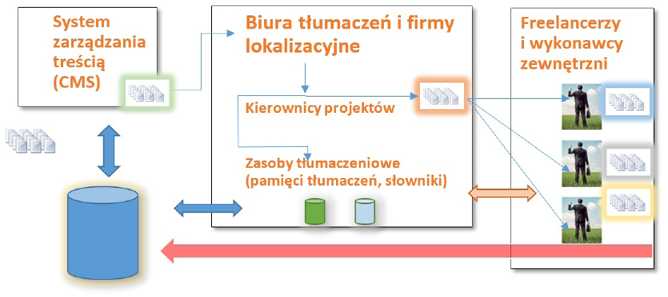
Rysunek 2.2. Bazy, tłumacze i ponadprzeciętna liczba strzałek
Projekty lokalizacyjne mogą być zorganizowane przeróżnie, ale łączy je planowana data udostępnienia aplikacji. Decyzja o tej dacie nie należy często ani do tłumaczy, ani do programistów, tylko do różnej maści handlowców, marketingowców i innych menedżerów, a przesłankami do jej ustalenia są często wydarzenia w świecie zewnętrznym, takie jak szał zakupów przed Bożym Narodzeniem czy działania konkurencji.
Kiedy tłumaczymy (i ile to potrwa)?
Przyjrzyjmy się na początek, jak może przebiegać cykl produkcji oprogramowania. To, co będzie się działo w projekcie lokalizacyjnym, na pewno będzie nosić jego ślady. Zacznijmy od nieco historycznego już modelu sekwencyjnego (zwanego też z angielska waterfall — wodospad): tu wszystko dzieje się po kolei (rysunek 2.3).
 Rysunek 2.3. Wodospady łez klientów, którzy muszą czekać na zakończenie lokalizacji produktu
Rysunek 2.3. Wodospady łez klientów, którzy muszą czekać na zakończenie lokalizacji produktu
Model ten jest stosowany, gdy:
- oprogramowanie ma długi cykl wydawniczy;
- oprogramowanie zlokalizowane będzie wydane o wiele później niż w oryginalnej wersji językowej;
- liczba słów do przetłumaczenia jest względnie niewielka, gdyż tłumaczenie jest tu dodatkowym procesem, który nie przebiega
- równolegle z innymi (więc ogromny projekt automatycznie powodowałby ogromne opóźnienia);
- czas dotarcia na rynek nie ma większego znaczenia.
Oprogramowanie tworzy się dziś zupełnie inaczej niż 20 lat temu, a czas dotarcia produktu do odbiorcy stał się jeszcze bardziej istotny, więc model sekwencyjny powoli wychodzi z użycia. Czasem jednak można jeszcze spotkać się z takim procesem wśród firm, które podejmują się lokalizacji swojego produktu po raz pierwszy.
Im bardziej dynamiczna staje się produkcja oprogramowania, tym lepiej sprawdza się model interaktywny, czyli kaskadowy: do gry wchodzą kolejne dostawy i wersje (rysunek 2.4).

Rysunek 2.4. Lokalizowanie produktu, gdy trwają już prace nad jego nowszą wersją, jest trochę jak kupienie nowego samochodu tuż przed premierą wersji po face liftingu
Model ten przydaje się, gdy:
- zlokalizowane oprogramowanie będzie dostarczane równocześnie z oryginalną wersją językową;
- lokalizacja musi rozpocząć się jeszcze w trakcie powstawania kodu (ze względu na dużą ilość tekstu);
- oprogramowanie często podlega zmianom;
- oprogramowanie nie ulega znaczącym przeobrażeniom w warstwie interfejsu, dzięki czemu będzie możliwe skorzystanie z istniejących tłumaczeń;
- istotny jest czas dotarcia na rynek docelowy.
Od paru lat producenci oprogramowania mówią coraz głośniej, że takie zagęszczenie ruchów to jeszcze za mało. Klient, który żyje w świecie ciągłego strumienia informacji i natychmiastowej komunikacji w obrębie całej planety, nie cechuje się specjalną cierpliwością wobec produktów, które wybiera. Mają być gotowe jak najszybciej, naprawiane i udoskonalane cały czas. Produkt, który tkwi w zastoju, nie pokazuje częstych aktualizacji i działań rynkowych, jest postrzegany jako produkt martwy i z innej epoki. Nic więc dziwnego, że w konsekwencji od programistów oczekuje się szybszego dostarczania działającego kodu i szybkich reakcji na oczekiwania klienta. W świecie rosnących wymagań i coraz większego pędu trzeba umiejętnie żonglować czasem pracy programisty, testowaniem i promocją produktu.
Model lokalizacji oprogramowania Agile, czyli tzw. zwinny, wydaje się najlepiej dopasowany do potrzeb współczesnego rynku: oprogramowanie powstaje po kawałeczku, a tłumaczenia muszą nadążać (rysunek 2.5).

Rysunek 2.5. Projekty Agile są wiecznie niewyspane[3]
Model ten zakłada ciągły cykl przepływu pracy i jest stosowany, gdy:
- zlokalizowana wersja musi być dostępna niemal natychmiast, z czasem projektów liczonym w dniach (czasem nawet godzinach!), a nie tygodniach lub miesiącach;
- oprogramowania będzie testowane w wielu językach i dostarczane równocześnie na wiele rynków;
- klient może zmodyfikować wymagania względem produktu w trakcie jego tworzenia;
- bardzo istotny jest czas dotarcia do klienta.
Model Agile współgra z koncepcją Continuous Delivery polegającą na (niemal) ciągłym wdrażaniu zmian do produktu. Najlepszym przykładem są aplikacje dla urządzeń mobilnych, w których trudno wręcz zauważyć nowe wersje; nasz smartfon po prostu co jakiś czas pobiera aktualizację, a apka zaskakuje nas kolejnymi ulepszeniami. Analogicznie wygląda to dla wielu aplikacji dostępnych przez WWW: ich producent nie ogłasza nowej wersji, tylko po prostu zmienia wygląd i funkcjonalność portalu. Warto pamiętać, że pod względem procesów, metodyki pracy i użycia technologii branża lokalizacyjna jest zwykle parę lat do tyłu w stosunku do branży IT. Najlepszym dowodem na to jest fakt, że programiści metodykę Agile (a właściwie różne metodyki spełniające jej założenia) znają od roku 2001. To wówczas uznano, że w dużym zespole z bardzo tradycyjnym podejściem do zarządzania projektami trudno wprowadzać szybkie zmiany, których oczekuje klient końcowy — przełożone na bardziej jednoznaczne z perspektywy programistów zapisy w postaci zaktualizowanej listy wymagań i specyfikacji produktu. Aby skuteczniej i szybciej reagować na takie sytuacje, część obowiązków kierownika projektów musiało przejść do roli programisty. Agile ma w założeniu sprawiać, że małe zespoły programistów będą gotowe na częste zmiany wymagań i będą w stanie samodzielnie zarządzać swoją codzienną pracą. Minusem, ale i nieodzowną konsekwencją Agile jest to, że programiści w zespołach skupiają się na komunikacji i realizowaniu zadań, ale niekoniecznie spędzają wiele czasu na dokumentowaniu tego, co tworzą. Metodyka Agile będzie więc w znacznym stopniu przygotowywać zespół na zmiany w projekcie, nawet jeśli wystąpią na późniejszym etapie pracy. Kluczem do jej skutecznego stosowania jest nacisk na jakość kodu i organizację pracy — można powiedzieć, że dzięki tej metodyce oprogramowanie powstaje szybciej, ale też zwiększa się wpływ ewentualnych błędów programisty na projekt. Aby zatem przeciwdziałać długofalowym konsekwencjom, wszelkie inspekcje wymagań i aktualizacje wydań oprogramowania są przeprowadzane znacznie częściej niż w stosowanych dawniej metodykach wytwarzania oprogramowania[4]. Zmiany w sposobie produkcji oprogramowania siłą rzeczy muszą wpłynąć na to, jak pracują dzisiejsze firmy lokalizacyjne i tłumacze. Zrozumienie tych konsekwencji sprawi, że dzisiejsze realia tysięcy małych i coraz bardziej rozdrabniających się projektów na rynku nie są specjalnie zaskakujące.
Co tłumaczymy (i jak to wygląda)?
Choć każda firma i organizacja ma poczucie szczególnej roli, jaką pełni w świecie biznesu (lub dowolnym innym), oraz przeświadczenie o absolutnej wyjątkowości oferowanych usług i produktów, to trzeba stwierdzić, że projekty lokalizacyjne bardzo często bywają do siebie podobne pod względem typu, formatu danych, struktury, a nawet celu. Projekty można zatem podzielić według zawartości na kilka najpopularniejszych grup:
- oprogramowanie (elementy interfejsu, komunikaty wyświetlane przez program i wszelkie potrzebne do tego zasoby tekstowe oraz graficzne);
- pomoc elektroniczna (system pomocy dołączony do aplikacji, pomoc online na stronach internetowych, serwisy wsparcia technicznego, serwisy społecznościowe produktów, bazy wiedzy itp.);
- dokumentacja (zarówno wersje do druku, jak i dokumentacja do umieszczenia online, raporty, ekspertyzy i wszelkie inne dokumenty w firmie, które wymagają lokalizacji);
- umowy licencyjne, gwarancje i inne teksty prawne, które regulują sposób korzystania z oprogramowania lub usługi.
Lokalizacja oprogramowania to również swoisty kontener na inne dziedziny. Na przykład aplikacja do prowadzenia książki przychodów i rozchodów będzie w sposób oczywisty zawierać fragmenty IT, ale będzie również sięgać do finansów, a aplikacja do obsługi EKG to połączenie informatyki, elektroniki i kardiologii. Prawdopodobnie najobszerniejszy pod względem wolumenu tłumaczeń typ projektu stanowi dokumentacja. Interfejs na ekranie zawsze zajmie mniej miejsca niż instrukcja jego użytkowania i opis działania. Sposób tworzenia dokumentacji w ciągu ostatnich dwóch dekad ulega stałym przeobrażeniom. Powszechna wydaje się tendencja do umieszczania dokumentacji online i rezygnowania — tam, gdzie to możliwe — z wersji drukowanej. Dziś niemal każda aplikacja instalowana na komputerze po kliknięciu opcji „Pomoc” odsyła online i próbuje łączyć się z Internetem. Czy jednak na pewno można ogłosić śmierć papieru (poza tym, na którym drukuje się gwarancje)? Pod koniec 2015 roku niemiecka organizacja Tekom zapytała około 1700 autorów dokumentacji (z angielska: technical writerów) o to, czy tworzona przez nich dokumentacja jest drukowana, czy umieszczana online. Ogromnym zaskoczeniem był wynik tej ankiety — aż 96% odpowiedziało, że tworzą głównie pod kątem formatu PDF i wydruku. Zaledwie 30% dokumentacji powstaje z myślą o publikacji online. Głównym powodem takiego stanu rzeczy są wymogi prawne i oczekiwania klientów danej firmy. Nie można też nie doceniać czynnika „bo zawsze tak robiliśmy”, który sprawia, że dokumenty drukowane powstają siłą rozpędu, dopóki firma nie postanowi być bardzo oszczędna lub bardzo, bardzo eko.
Wyodrębnianie materiału do lokalizacji
Wielkie szuflady i kartoteki pełne szpargałów przetrwały już tylko w części organizacji publicznych. Duże firmy od dawna próbują zapanować nad tym, co i gdzie przechowują oraz co, kto, kiedy i jak napisał. Rozwiązaniem, które pozwala zachować kontrolę nad słowem pisanym na komputerach, są systemy zarządzania treścią (ang. CMS — Content Management Systems).
Najprościej można je sobie wyobrazić jako bazy danych przechowujące w drzewiastej strukturze informacje, gdzie czego szukać (rysunek 2.6). Często zawierające nie tylko adresy, ale i same pliki.
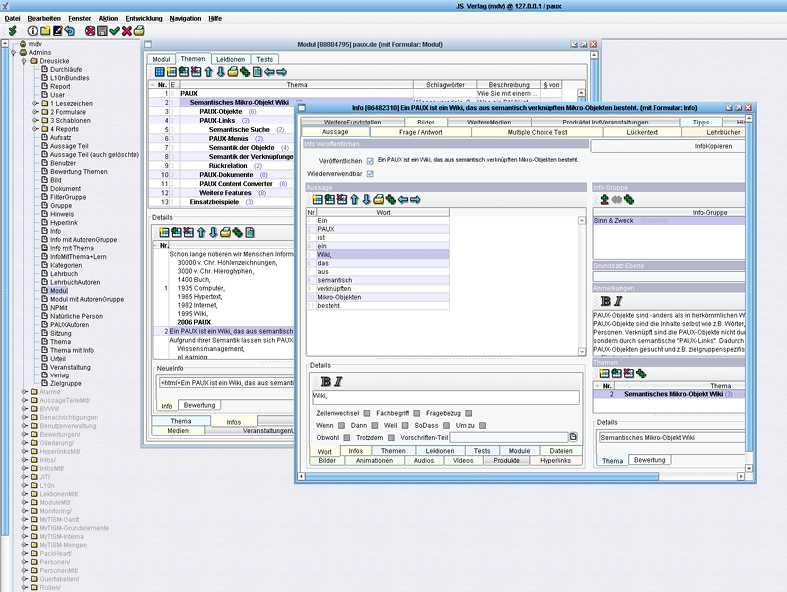
Rysunek 2.6. Przykładowy system przytłaczania treścią[5]
CMS-y w dużych organizacjach zawierają często miliony pozycji i odniesień, zatem trzymanie całości w ryzach może zapewnić już tylko automat. Jak jednak przechowywanie dokumentów w CMS-ach ma się do lokalizacji oprogramowania? Wyobraźmy sobie, że do systemu trafia nowa partia dokumentów wymagających tłumaczenia lub programista zwinnie (!) załadował do systemu nowy moduł zawierający zasoby do lokalizacji. Od tej pory scenariusze są dwa. Pierwszy zakłada, że nad procesem decyzyjnym dotyczącym zlecenia tłumaczeń w każdym wypadku czuwa człowiek. Oczywiście będzie to pracownik, który ma wsparcie w postaci systemu CMS ułatwiającego zapanowanie nad sytuacją. System ten radzi sobie z tysiącami projektów i ogromną liczbą zasobów. Zdarza się, że taki centralny CMS odpowiada za wszystkie zlecane przez daną organizację tłumaczenia: od tych naprawdę małych po ogromne wolumeny. Każdorazowo jednak decyzję podejmuje osoba odpowiedzialna za wydzielenie zasobów do tłumaczenia, na przykład zaznaczenie odpowiedniego modułu i skierowanie go do lokalizacji. Alternatywą jest stosowanie osobnych CMS-ów do każdego projektu, na przykład produktu programistycznego (aplikacji), i wybieranie zasobów do tłumaczenia na tej samej zasadzie, ale wyłącznie w obrębie danego projektu. Warto zauważyć, że taki scenariusz ma szansę powodzenia, jeśli projekty są kompletne (mają z góry znaną strukturę). Również projekty o krytycznym znaczeniu będą wymagały autoryzacji człowieka. Coraz częściej jednak produkty żyją praktycznie cały czas i są aktualizowane non stop. Angażowanie specjalnego kierownika projektów do każdorazowego autoryzowania zlecenia lokalizacji przy tysiącach zleceń w małych paczkach powodowałoby ogromne opóźnienia. Jak zatem można sobie poradzić z taką sytuacją? CMS-y konfigurowane są tak, że nad aktualną sytuacją czuwa specjalny agent-aplikacja. Firma ustala na przykład, że wszystkie moduły kluczowej aplikacji mają być zawsze lokalizowane. W takim przypadku każdy fragment kodu (lub dokumentacji), który zostanie załadowany do systemu, natychmiast jest wyodrębniany w postaci specjalnej paczki lokalizacyjnej i automatycznie wysyłany do wybranego wcześniej podwykonawcy. Cały proces odbywa się automatycznie. Alternatywą jest przydzielenie agentowi pewnej swobody działania — małe zlecenia są natychmiast wysyłane do lokalizacji, a duże wymagają dodatkowej autoryzacji człowieka. Można śmiało założyć, że już wkrótce nasze lodówki będą w ten sam sposób robić zakupy. Choć może nie tak śmiało, bo perspektywa zhakowanej lodówki wygląda jednak dość przerażająco. --- [1] Przykład pochodzi z języka gamma, https://www.dobreprogramy.pl/aeroflyluby/Budujemy-wlasnego-asemblera,41816.html. [2] Źródło: Helena S. Chapman, IBM Corporate Globalization Director: „Only one-tenth of the iceberg is above water. Translation is all you see” (tłumaczenie: Nad wodą widać tylko jedną dziesiątą góry lodowej). [3] Źródło: SDL. [4] Złośliwi twierdzą, że triumfalny pochód metodyki Agile przez różnorodne rodzaje oprogramowania nosi cechy „kultu cargo”, czyli przekonania pewnych mieszkańców wysp na Pacyfiku, że jeśli będą wiernie powtarzać zachowania pracowników lotniska i kontroli lotów, to przyleci samolot pełen wszelkiego dobra. Źródło: https://agileszkolenia.pl/blog/agile-kult-cargo/. [5] Źródło: M. Dreusicke, 2006.
 Fragment pochodzi z książki "Programiści i tłumacze. Wprowadzenie do lokalizacji oprogramowania" (Wydawnictwo Helion 2017).Książka >>Ebook >>
Fragment pochodzi z książki "Programiści i tłumacze. Wprowadzenie do lokalizacji oprogramowania" (Wydawnictwo Helion 2017).Książka >>Ebook >>
Zobacz nasze propozycje
-

-
książka
-
ebook
(41,40 zł najniższa cena z 30 dni)
46.23 zł
69.00 zł (-33%) -
-

-
książka
-
ebook
-
audiobook
(35,40 zł najniższa cena z 30 dni)
39.53 zł
59.00 zł (-33%) -
-

-
książka
-
ebook
(77,40 zł najniższa cena z 30 dni)
86.43 zł
129.00 zł (-33%) -
-

-
książka
-
ebook
-
audiobook
Czasowo niedostępna
-
-

-
książka
-
ebook
(53,40 zł najniższa cena z 30 dni)
53.40 zł
89.00 zł (-40%) -
-

-
książka
-
ebook
(83,40 zł najniższa cena z 30 dni)
93.12 zł
139.00 zł (-33%) -
-

-
kurs
(134,25 zł najniższa cena z 30 dni)
134.25 zł
179.00 zł (-25%) -
-

-
książka
-
ebook
(89,40 zł najniższa cena z 30 dni)
99.83 zł
149.00 zł (-33%) -
-

-
kurs
(141,75 zł najniższa cena z 30 dni)
141.75 zł
189.00 zł (-25%) -
-

-
książka
-
ebook
Czasowo niedostępna
-
-

-
książka
-
ebook
(71,40 zł najniższa cena z 30 dni)
79.73 zł
119.00 zł (-33%) -
-

-
książka
-
ebook
(53,40 zł najniższa cena z 30 dni)
59.63 zł
89.00 zł (-33%) -
-

-
książka
-
ebook
(53,40 zł najniższa cena z 30 dni)
59.63 zł
89.00 zł (-33%) -
-

-
książka
-
ebook
(53,40 zł najniższa cena z 30 dni)
59.63 zł
89.00 zł (-33%) -
-

-
książka
-
ebook
(77,40 zł najniższa cena z 30 dni)
86.43 zł
129.00 zł (-33%) -
-

-
książka
-
ebook
(47,40 zł najniższa cena z 30 dni)
52.93 zł
79.00 zł (-33%) -
-

-
książka
-
ebook
(52,20 zł najniższa cena z 30 dni)
58.29 zł
87.00 zł (-33%) -
-

-
książka
-
ebook
-
audiobook
(29,94 zł najniższa cena z 30 dni)
33.43 zł
49.90 zł (-33%) -
-

-
książka
-
ebook
(23,94 zł najniższa cena z 30 dni)
26.73 zł
39.90 zł (-33%) -
-
-
kurs
(149,25 zł najniższa cena z 30 dni)
149.25 zł
199.00 zł (-25%) -





