
![SEO, czyli sztuka optymalizacji witryn dla wyszukiwarek [FRAGMENT]](https://static01.helion.com.pl/helion/images/aktualnosci/seowit.png)
SEO, czyli sztuka optymalizacji witryn dla wyszukiwarek [FRAGMENT]
„To innowacyjna książka, która już na pierwszej stronie zawiera informacje mogące odmienić Twój los i przyszłość Twojej firmy. Znajdziesz w niej mnóstwo cennych informacji, dzięki którym zaoszczędzisz wiele godzin i zarobisz miliony na promocji swojej działalności w internecie. Przedstawione pojęcia i idee są zrozumiałe i łatwe do zastosowania, co jest kluczowe dla marek i firm skupionych na swoim produkcie lub świadczonych usługach, ale chcących być na bieżąco ze światem SEO. Autorzy tej książki — Stephan Spencer, Eric Enge i Jessie Stricchiola — wspólnie mają kilkadziesiąt lat doświadczenia i opisują stosowane przez siebie nowatorskie metody, badania oraz strategie, dzięki czemu my możemy osiągnąć sukcesy w SEO, oszczędzając cenny czas i pieniądze. W trzecim wydaniu swojej książki autorzy opisali najnowsze zmiany oraz przedstawili najbardziej aktualne, dokładne i sprawdzone techniki wyprzedzania konkurencji. Jak podkreślam w wielu swoich przemówieniach, jeśli się nie rozwijasz, to znaczy, że się cofasz. Książka SEO, czyli sztuka optymalizacji witryn dla wyszukiwarek zawiera najświeższe informacje potrzebne do tego, by być konkurencyjnym w SEO. Wszystko, czego potrzebujesz, jest na wyciągnięcie ręki”.
Najważniejsze zagadnienia omówione w książce:
- teoretyczne podstawy i praktyczne zasady SEO
- wykorzystywanie mediów społecznościowych i danych użytkownika
- projektowanie witryny z uwzględnieniem SEO i zasad marketingu
- treści algorytmy Google’a i innych wyszukiwarek
- własne badania i analizy dla potrzeb SEO
Rzuć okiem na poniższy fragment, który przybliży Ci wstęp temat zachowań użytkownika.
Odgadywanie zamiarów użytkownika i zwracanie trafnych, aktualnych treści
Nowoczesne komercyjne wyszukiwarki polegają na nowej dziedzinie wiedzy zwanej wydobywaniem informacji (ang. information retrieval — IR). Ten dział nauki powstał w drugiej połowie dwudziestego wieku, gdy systemy wyszukiwania zaczęły zasilać komputery w bibliotekach, ośrodkach badawczych i rządowych laboratoriach. Już we wczesnej fazie pracy na tymi systemami naukowcy zdali sobie sprawę, że w wyszukiwaniu istotną rolę odgrywają dwa czynniki: trafność i waga (oba zdefiniowaliśmy we wcześniejszej części tego rozdziału). Aby zmierzyć te czynniki, wyszukiwarki przeprowadzają analizę dokumentu (w tym analizę semantyczną idei we wszystkich dokumentach) i analizę odnośników. Analiza dokumentu a łączność semantyczna W czasie analizy dokumentu wyszukiwarki przeszukują w poszukiwaniu pojęć wszystkie jego ważniejsze obszary — tytuł, metadane, znaczniki nagłówków oraz sam tekst. Usiłują też ustalić jakość dokumentu na podstawie wielu czynników. Sama analiza dokumentu nie wystarczy nowoczesnym wyszukiwarkom, więc polegają one na badaniu tzw. semantycznej łączności. Pojęcie to dotyczy słów lub fraz, które w naturalny sposób łączą się w skojarzenia. Przykładowo: widząc słowo aloha, skojarzysz je automatycznie z Hawajami, a nie z Florydą. Wyszukiwarki dynamicznie budują własne tezaurusy i słowniki, które pomagają im określić, w jaki sposób niektóre terminy i tematy łączą się ze sobą. Przechodząc przez olbrzymią bazę danych treści sieciowych, powołują się na teorię zbioru rozmytego i pewne równania, które pomagają im połączyć pojęcia i zacząć postrzegać strony oraz witryny w sposób przypominający pojmowanie ludzkie. Specjalista SEO nie musi co prawda używać specjalistycznych narzędzi do mierzenia semantycznej łączności na stronie, aby zoptymalizować swoją witrynę, lecz wybitni fachowcy, którzy pragną uzyskać przewagę nad konkurencją, poprawiając łączność, mogą uzyskać pozytywne rezultaty w następujących aspektach:
- Mierzenie poprawności słów kluczowych.
- Mierzenie, jakie słowa kluczowe warto umieścić na stronie poświęconej danej tematyce.
- Mierzenie powiązania pomiędzy tekstem a wysoko ocenianymi stronami, witrynami.
- Znajdowanie stron, które zapewniają tematycznie trafne wyniki.
Choć sama metoda mierzenia łączności semantycznej jest bardzo techniczna, specjaliści SEO muszą znać jedynie jej pryncypia, aby zdobyć wartościowe informacje. Warto pamiętać, że choć jako dyscyplina wiedzy odzyskiwanie informacji używa wielu setek technicznych i trudnych do zrozumienia terminów, całość może być podzielona na części łatwe do zrozumienia nawet dla nowicjusza SEO. Oto kilka podstawowych typów wyszukiwań zdefiniowanych w IR: Wyszukiwanie fraz sąsiadujących
W wyszukiwaniu fraz sąsiadujących wykorzystuje się kolejność słów w wyrażeniu przy przeszukiwaniu dokumentów. Przykładowo: szukając wyrażenia "słodka niemiecka musztarda", określasz dokładne dopasowanie. Gdybyśmy usunęli cudzysłów, dopasowanie fraz sąsiadujących w dalszym ciągu odgrywałoby ważną rolę w wyszukiwaniu, jednak samo wyszukiwanie nie zwracałoby dokładnie dopasowanych wyników w rodzaju słodka musztarda — Niemcy.
Logika rozmytaW logice rozmytej dwie kategorie myślenia nie są zawsze sprzeczne — nie ma podziału na prawdę i fałsz. Przykładem takiej logiki jest traktowanie słonecznego dnia (np. jeżeli tylko 50% nieba jest zakryte przez chmury, to czy możemy mówić o pochmurnym dniu?). Jednym z najczęstszych sposobów zastosowania logiki rozmytej jest wykrywanie błędów ortograficznych w zapytaniu.
Wyszukiwanie logiczneW wyszukiwaniu logicznym używa się logicznych operacji AND, OR lub NOT. Ten typ logiki używany jest do rozwinięcia lub ograniczenia zakresu wyszukiwania dokumentów.
Ważenie terminówPojęcie to odnosi się do próby określenia wagi danego terminu względem zapytania. Cała koncepcja polega na nadaniu pewnym terminom większej wagi niż innym, tak by mogły zostać wygenerowane lepsze wyniki wyszukiwania. Przykładowo: słowo „lub” w zapytaniu otrzyma mniejszą wagę w wynikach wyszukiwania, ponieważ pojawia się praktycznie we wszystkich napisanych po polsku dokumentach. W słowie tym nie ma nic niezwykłego, więc nie pomoże ono w wybraniu właściwego dokumentu.
Modele IR (w tym wyszukiwarki) używają teorii zbiorów rozmytych (interpretacji logiki rozmytej opracowanej przez dr. Lotfi Zadeha w 1969 roku), by ustalić łączność semantyczną pomiędzy dwoma słowami. Zamiast polegać na słowniku lub tezaurusie do ustalenia, jak mocno dwa słowa są ze sobą powiązane, system IR może wykorzystać pokaźny zasób danych, żeby samodzielnie ustalić stopień współzależności. Choć opis procesu może brzmieć skomplikowanie, jego podstawy są proste. Wyszukiwarki działają w oparciu o logikę maszynową (prawda – fałsz, tak – nie itp.). Logika ta przewyższa pod pewnymi względami ludzkie rozumowanie, lecz nie sprawdza się w przypadku typowo ludzkich problemów. Zjawiska, które dla ludzi są intuicyjne, są bardzo trudne do zrozumienia dla komputerów. Na przykład: pomarańcze i banany są owocami, ale banany i pomarańcze nie są okrągłe. Dla człowieka jest to intuicyjne. Dla maszyny zrozumienie tej koncepcji i wybranie spośród wielu cech tej właściwej wymaga zastosowania semantycznej łączności. Cały olbrzymi zasób wiedzy ludzkości w sieci może zostać zapisany w indeksach systemu, a następnie przeanalizowany tak, że w rezultacie stworzony zostanie sztuczny, choć przypominający ludzki model zależności. Dzięki niemu maszyna będzie w stanie określić, że pomarańcza jest okrągła, a banan nie, skanując te słowa w swoich indeksach i zauważając, że słowa „okrągły” i „banan” nie są ze sobą zbieżne, przynajmniej tak często jak słowa „pomarańcza” i „okrągły”. W tym miejscu do gry wchodzi logika rozmyta. Wykorzystanie teorii zbiorów rozmytych pomaga komputerowi zrozumieć, w jaki sposób różne terminy są od siebie uzależnione, poprzez zmierzenie, jak często występują razem w jakich kontekstach. Przykładowo: przy użyciu LSA wyszukiwarka mogłaby rozpoznać, iż wycieczki do zoo wiążą się z podziwianiem fauny oraz ze zwiedzaniem. Spróbuj teraz wykonać wyszukiwanie terminu zoo wycieczki. Zwróć uwagę na to, że zwrócone w wynikach wyszukiwania dla tego wyrażenia słowa napisane z pogrubieniem pasują do słów oznaczonych kursywą w poprzednim akapicie. Google rozpoznaje, które terminy często występują zbieżnie (razem na tej samej stronie lub w niedalekiej odległości) w jego indeksach. Twórcy wyszukiwarek dopracowywali tego typu technologie przez całe lata. We wrześniu 2013 roku firma Google poinformowała bez rozgłosu, że „przepisała” swoją wyszukiwarkę od nowa i nadała jej nazwę Hummingbird (koliber — https://bit.ly/hummingbird_reveal). Akcja ta została w dużej części przeprowadzona w celu zapewnienia sobie przez Google możliwości korzystania z nowych technologii rozpoznawania relacji. Jeśli na przykład skorzystasz z funkcji wyszukiwania głosowego wyszukiwarki Google (kliknij ikonę mikrofonu znajdującą się po prawej stronie pola wyszukiwania na stronie Google.com) i zadasz pytanie: „Kim jest Tom Brady?”, to otrzymasz odpowiedź w wynikach wyszukiwania, że jest to amerykański futbolista grający na pozycji rozgrywającego w zespole New England Patriots w lidze National Football League. Jest to dowód na to, że Google rozumie wiele aspektów dotyczących Toma Brady’ego, m.in.:
- Mężczyzna ten ma pewien zawód: jest rozgrywającym, gra w futbol amerykański (określenie futbol jest używane w innym znaczeniu poza USA i Kanadą).
- Mężczyzna ten gra w zespole: New England Patriots.
- Zespół New England Patriots należy do ligi NFL.
Jest to duży postęp w stosunku do tego, jak wyglądało wyszukiwanie jeszcze w roku 2012. Funkcja ta ma nawet jeszcze szersze możliwości. Jeśli na przykład spytamy wyszukiwarkę: „Kim jest jego żona?”, to również otrzymamy poprawną odpowiedź (rysunek 2.22).
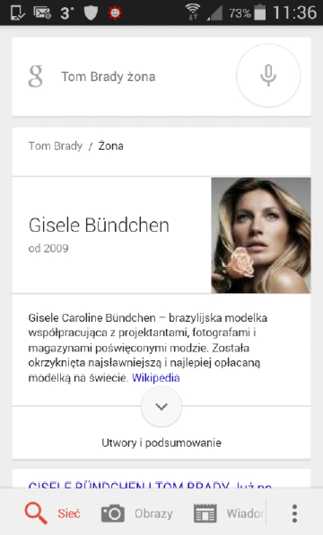
Rysunek 2.22. Gisele Bündchen jest żoną Toma Brady’ego
Zauważ, że w drugim zapytaniu nie trzeba było powtarzać nazwiska Tom Brady, ponieważ wyszukiwarka Google zapamiętała kontekst konwersacji w tym sensie, że powiązała słowo „jego” z nazwiskiem sportowca. Dalej można wypytywać, „Czy on ma dzieci?” i na to pytanie Google również odpowie.
Dla specjalisty SEO są to ważne informacje mówiące wiele o tym, na jakiej zasadzie przeglądarki tworzą powiązania między słowami, frazami i ideami w sieci. Semantyczna łączność zaczyna odgrywać coraz większą rolę w algorytmach wyszukiwania, więc możesz spodziewać się, że tematyka stron, witryn i linków będzie w przyszłości jeszcze ważniejsza. Fakt, że wyszukiwarki będą w stanie dokonać rozróżnienia pomiędzy motywami, koncepcjami, i wyróżnić z nich konkretne treści, linki i strony, które nie pasują do ogólnej treści, może przełożyć się znacznie na Twoją działalność. Jakość treści i zaangażowanie użytkowników Wyszukiwarki usiłują też zmierzyć jakość i wyjątkowość zawartości witryny. Podstawowym podejściem jest ocena poprawności całego dokumentu. Na przykład: jeżeli na stronie roi się od ortograficznych i gramatycznych błędów, może to zostać zinterpretowane jako brak należytej uwagi redaktorskiej[5]. Wyszukiwarki potrafią też ocenić czytelność dokumentu. Podstawową metryką jest indeks czytelności Flescha-Kincaida, w którym brane są pod uwagę takie czynniki jak średnia długość słów oraz liczba słów w zdaniu. Dzięki temu oceniany jest poziom wykształcenia wymagany do zrozumienia zdania. Wyobraź sobie stronę, na której sprzedaje się zabawki dla dzieci, lecz z wyliczeń wynika, że treść odpowiada poziomowi intelektualnemu studenta ostatnich lat studiów. Jest to kolejna wskazówka, że tekst na stronie jest niedopracowany. Kolejną metodą, której przeglądarki często używają do ocenienia jakości strony internetowej, jest zmierzenie interakcji z użytkownikiem. Przykładowo: jeżeli duża liczba użytkowników, którzy klikają wynik wyszukiwania, natychmiast wraca na stronę wynikową i przechodzi do następnego rezultatu, może do oznaczać, że jakość strony jest niska. Stopień zaangażowania w czytaną stronę stał się czynnikiem rankingowym wraz z opublikowaniem przez Google uaktualnienia Panda w lutym 2011 roku[6]. Google ma dostęp do olbrzymiego zbioru źródeł danych, które może wykorzystać do zmierzenia aktywności użytkowników na stronie. Oczywiście dostępność tych informacji nie oznacza automatycznie, że Google na pewno z nich korzysta jako z czynnika rankingowego. Oto niektóre spośród tych źródeł: Interakcja z wynikami wyszukiwania
Gdy użytkownik kliknie jedną z pozycji na stronie wynikowej i przejdzie na Twoją witrynę, po czym kliknie przycisk Powrót i wybierze następny rezultat na początkowej liście, będzie to negatywnym znakiem rankingowym. Fakt, że wyniki znajdujące się na liście niżej niż Twoja witryna są klikane częściej, może zostać zinterpretowany jako pozytywny sygnał rankingowy dla nich, ale negatywny dla Ciebie. To, czy wyszukiwarka weźmie te sygnały pod uwagę i jak poważnie je potraktuje, jest niemożliwe do ustalenia.
Google AnalyticsNie do końca wiadomo, jaki odsetek witryn w sieci korzysta z narzędzia Google Analytics. Przeprowadzone w 2008 roku przez portal immeria.net badania wykazały, że Google Analytics zdobyło 59% rynku[7]. Z kolei na blogu Metric Mail przedstawiono wyniki testu miliona witryn — okazało się, że około 50% z nich korzystało z Google Analytics[8]. Właśnie dzięki temu Google jest w stanie uzyskać szczegółowe dane o tym, co się dzieje na sporej części witryn na całym świecie.
Google Analytics informuje Google o wielu aspektach użytkowania tych witryn. Określa: Wskaźnik porzucenia
Odsetek użytkowników, którzy wczytali tylko jedną stronę z Twojej witryny.
Czas spędzony na witrynieŚrednia ilość czasu, jaką użytkownicy spędzili na Twojej witrynie. Wiedz jednak, że Google Analytics pobiera nowe informacje dopiero po załadowaniu następnej strony z witryny, więc jeżeli użytkownik przejrzy tylko jedną stronę, wyszukiwarka nie będzie w stanie ustalić, ile czasu na niej spędził. Wskaźnik czasu mówi o średnim czasie, jaki upłynął pomiędzy załadowaniem pierwszej i ostatniej strony, lecz nie wykazuje, ile czasu użytkownik spędził, przeglądając ostatni dokument.
Średnia liczba przejrzanych stron na użytkownikaŚrednia liczba stron wczytanych przez użytkownika.
Pasek wyszukiwania GoogleNie wiadomo dokładnie, ile osób używa paska wyszukiwania Google, lecz według nas mogą to być miliony. Dzięki temu Google może dokładnie śledzić zachowanie tych użytkowników w sieci. W odróżnieniu od Google Analytics pasek narzędzi Google mierzy czas od przybycia użytkownika na witrynę do załadowania strony z innej domeny. Może on również mierzyć wskaźnik porzucenia i liczbę przejrzanych przez użytkownika stron.
Przycisk Google +1Przycisk ten pozwala użytkownikom głosować na daną stronę. Aktualnie brak dowodów na to, by było to wykorzystywane przez Google jako czynnik rankingowy, ale teoretycznie jest taka możliwość. Szerzej na ten temat piszemy w rozdziale 8.
Rozszerzenie Chrome Personal BlocklistFirma Google udostępnia rozszerzenie do przeglądarki o nazwie Chrome Personal Blocklist (https://bit.ly/block_sites_ext). Dzięki niemu użytkownicy przeglądarek Chrome mogą wskazywać wyniki wyszukiwania, które im nie odpowiadają. Po raz pierwszy informacje z tego rozszerzenia zostały wykorzystane w algorytmie Panda, którego zadaniem jest mierzenie jakości treści. Szerzej o tym algorytmie piszemy w rozdziale 9.
Goo.glFirma Google ma też własny system skracania adresów URL. Dzięki temu narzędziu Google jest w stanie śledzić, jakie treści są współdzielone między użytkownikami i które z nich są wybierane najczęściej nawet w zamkniętych środowiskach — tam gdzie szperacze Google zwykle nie mają dostępu
Można przypuszczać, że czynnikiem decydującym o pozycji na liście rankingowej jest to, jak Twoja witryna wypada w porównaniu z witrynami konkurencji. Jeżeli Twoja witryna jest oceniana wysoko w testach zaangażowania, może ona potencjalnie podnieść Twoją pozycję rankingową w odniesieniu do konkurencji. Nie wiadomo dokładnie, w jaki sposób wyszukiwarki korzystają ze zgromadzonych danych, więc większość z powyższych komentarzy to zaledwie spekulacje autorów tej książki na temat polityki Google w tym obszarze. Czynniki społeczne i stopień zaangażowania zostaną omówione bardziej szczegółowo w rozdziale 8. Analiza linków Analiza linków polega na sprawdzeniu, kto podaje odnośnik do witryny lub strony i co w ten sposób przekazuje na jej temat. Dzięki tej analizie wyszukiwarki potrafią rozpoznać, który podmiot jest połączony z którym (poprzez historię linków, dokumentację zarejestrowania witryny i inne źródła), komu warto zaufać ze względu na autorytet stron, które podają linki do danego dokumentu, oraz kontekstowe dane o witrynie, na której ów dokument jest hostowany (kto linkuje do tej witryny i o czym to świadczy itd.). Analiza linków nie sprowadza się tylko do policzenia wszystkich odnośników na stronie lub witrynie, ponieważ odnośniki nie są równe. Linki ze stron o wyższym autorytecie na zaufanej stronie będą ważniejsze niż linki z witryny o niższym autorytecie (dany link może być wart 10 milionów razy więcej niż inny). Autorytet witryny lub strony jest oceniany na podstawie analizy wzorców linkowania i analizy semantycznej. Załóżmy, że zainteresowała Cię strona poświęcona czesaniu psów. Wykorzystując zdolności analizy semantycznej, wyszukiwarki odnajdują zestaw stron poświęconych temu zagadnieniu. Wyszukiwarki określają następnie, do których z tych stron odwołują się najczęściej inne strony poświęcone czesaniu psów. Właśnie takie strony będą miały wyższy autorytet w porównaniu z innymi. Naturalnie w praktyce analiza linków jest odrobinę bardziej skomplikowana. Przypuśćmy, że istnieje pięć stron poświęconych czesaniu psów, na które powołuje się wiele innych dokumentów w sieci:
- Witryna A posiada 213 tematycznie powiązanych odnośników.
- Witryna B posiada 192 tematycznie powiązane odnośniki.
- Witryna C posiada 283 tematycznie powiązane odnośniki.
- Witryna D posiada 113 tematycznie powiązanych odnośników.
- Witryna E posiada 122 tematycznie powiązane odnośniki.
Co więcej, może się okazać, że witryny A, B, D i E odnoszą się do siebie nawzajem, ale żadna z nich nie odnosi się do witryny C. Wygląda więc na to, że witryna C przyciągnęła największą liczbę tematycznie trafnych linków, choć pozostałe witryny nie uznają jej za wartościowe źródło informacji. W tym przykładzie witryna C nie może zostać uznana za autorytet, ponieważ strony o podobnym temacie nie odwołują się do niej.
Koncepcja grupowania witryn na podstawie tego, jakie łącza prowadzą do nich i dokąd prowadzą łącza z nich, nazywana jest sąsiedztwem linków. Sąsiedztwo, w którym Twoja witryna egzystuje, mówi wiele o jej zakresie tematycznym, a liczba i jakość odnośników, które otrzymasz od sąsiadów, wskazuje, jak ważna jest ona na tle innych.
Nie jest jasne, do jakiego stopnia wyszukiwarki polegają na oszacowaniu sąsiednich linków — wierzy się, że nawet nietrafne strony pomagają w polepszeniu rankingu stron docelowych. Mimo to odnośnik z trafnej strony będzie oceniany wyżej w pozycji rankingowej niż link ze strony o innej tematyce.
Kolejnym ważnym czynnikiem w ustalaniu wartości odnośnika jest sposób jego wdrożenia na stronie i jego widoczność. Sam tekst odnośnika (czyli to, co widzi użytkownik, klikając link) jest istotnym sygnałem dla wyszukiwarek.
Tekst ten nazywa się kotwicą (ang. anchor tekst) i jeśli zawiera wiele słów kluczowych (odpowiadających docelowej frazie wyszukiwania), to potencjalnie może lepiej przyczynić się do poprawienia pozycji witryny w wynikach wyszukiwania niż odnośnik bez słów kluczowych. Hasło „strzyżenie i czesanie psów” będzie bardziej wartościowe w przypadku witryny fryzjera psów niż napis „Kliknij tutaj”. Miej się jednak na baczności. Jeżeli będziesz miał 10 000 linków z tekstem „strzyżenie i czesanie psów” i niewiele innych odnośników na stronie, nie będzie to wyglądać naturalnie i może spowodować obniżenie pozycji rankingowej.
Analiza semantyczna wartości linku nie ogranicza się do oceniania opisu linku. Jeśli na przykład link „strzyżenie i czesanie psów” pojawi się na stronie, która nie będzie miała nic wspólnego z psami ani z czesaniem, wartość tego linku będzie mniejsza niż linku ze strony o czesaniu psów. Wyszukiwarki obserwują również znajdującą się na stronie treść otaczającą link oraz ogólny kontekst wraz z autorytetem strony, która zapewnia odnośnik.
Wszystkie te czynniki są składowymi analizy linków i omówimy je szczegółowo w rozdziale 7.
Ocenianie sygnałów społecznościowych
Portale społecznościowe takie jak Facebook, Twitter i Google+ pozwoliły użytkownikom dzielić się swoimi treściami i nadawać im pewną wartość na wiele sposobów. Wielu specjalistów uważa więc, że sygnały te mogą być wykorzystywane jako czynnik rankingowy. Spekulacje te podsyciły jeszcze opublikowane w sierpniu 2013 roku przez portal Moz dane wskazujące na istnienie korelacji między liczbą punktów +1 i pozycją strony w Google.
Na rysunku 2.23 pokazano 10 pierwszych wyników z tych danych. Widać, że liczba kliknięć przycisku Google +1 jest na drugim miejscu pod względem siły korelacji z pozycją w rankingu.
 Rysunek 2.23. Dziesięć pierwszych wyników z badań korelacyjnych przeprowadzonych przez portal Moz w 2013 roku
Jednak z faktu, że zauważono korelację, nie wynika wcale, że rzeczywiście Google wykorzystuje liczbę kliknięć przycisku +1 jako sygnału rankingowego ani że takie sygnały podnoszą pozycję strony w wynikach wyszukiwania. Równie dobrze może to być znakiem tego, że dobra treść, do której prowadzi wiele odnośników (co, jak wiadomo, jest sygnałem podnoszącym stronę w rankingach), otrzymuje też wiele dowodów uznania w postaci kliknięć przycisku +1.
Agencja Stone Temple Consulting przeprowadziła własne badania mające na celu sprawdzenie, czy aktywność w portalu Google+ przekłada się na pozycję strony w wynikach wyszukiwania Google[9]. W tym przypadku nie znaleziono żadnych materialnych dowodów na to, że liczba udostępnień w Google+ lub kliknięć przycisku Google +1 ma wpływ na rankingi. Potencjał sygnałów z mediów społecznościowych jest szczegółowo opisany w rozdziale 8.
Aktualność ma znaczenie
W wielu wypadkach wyszukiwarkom opłaca się zwrócić wyniki ze starszych źródeł, które raz za razem przechodzą testy zaufania. Czasem jednak lepiej jest zwrócić odpowiedzi z nowszego źródła.
Na przykład w przypadku nagłej katastrofy — trzęsienia ziemi — pierwsze zapytania docierają do wyszukiwarki w ciągu kilku sekund, choć pierwsze artykuły pojawiają się w sieci dopiero w ciągu 15 minut.
W tego typu scenariuszach informacje powinny być odnajdywane i indeksowane w czasie najbardziej zbliżonym do rzeczywistego. Google nazywa takie podejście naciskiem na aktualność (ang. query deserves freshness — QDF). Według „New York Timesa” nacisk na aktualność definiuje kilka czynników[10], w tym:
Rysunek 2.23. Dziesięć pierwszych wyników z badań korelacyjnych przeprowadzonych przez portal Moz w 2013 roku
Jednak z faktu, że zauważono korelację, nie wynika wcale, że rzeczywiście Google wykorzystuje liczbę kliknięć przycisku +1 jako sygnału rankingowego ani że takie sygnały podnoszą pozycję strony w wynikach wyszukiwania. Równie dobrze może to być znakiem tego, że dobra treść, do której prowadzi wiele odnośników (co, jak wiadomo, jest sygnałem podnoszącym stronę w rankingach), otrzymuje też wiele dowodów uznania w postaci kliknięć przycisku +1.
Agencja Stone Temple Consulting przeprowadziła własne badania mające na celu sprawdzenie, czy aktywność w portalu Google+ przekłada się na pozycję strony w wynikach wyszukiwania Google[9]. W tym przypadku nie znaleziono żadnych materialnych dowodów na to, że liczba udostępnień w Google+ lub kliknięć przycisku Google +1 ma wpływ na rankingi. Potencjał sygnałów z mediów społecznościowych jest szczegółowo opisany w rozdziale 8.
Aktualność ma znaczenie
W wielu wypadkach wyszukiwarkom opłaca się zwrócić wyniki ze starszych źródeł, które raz za razem przechodzą testy zaufania. Czasem jednak lepiej jest zwrócić odpowiedzi z nowszego źródła.
Na przykład w przypadku nagłej katastrofy — trzęsienia ziemi — pierwsze zapytania docierają do wyszukiwarki w ciągu kilku sekund, choć pierwsze artykuły pojawiają się w sieci dopiero w ciągu 15 minut.
W tego typu scenariuszach informacje powinny być odnajdywane i indeksowane w czasie najbardziej zbliżonym do rzeczywistego. Google nazywa takie podejście naciskiem na aktualność (ang. query deserves freshness — QDF). Według „New York Timesa” nacisk na aktualność definiuje kilka czynników[10], w tym:
- liczba wyszukiwań danego terminu;
- stopień omówienia w prasie;
- stopień omówienia w blogach.
Podejście QDF dotyczy bieżących wiadomości krążących w sieci, jak również informacji komercyjnych w rodzaju obniżek cen, pojawienia się nowych produktów, o których słyszy się w mediach i które naturalnie generują wiele wyszukiwań. Spekuluje się też, że Google ma w większym stopniu stosować podejście QDF do witryn o wyższym wskaźniku PageRank[11]. Dlaczego algorytmy wyszukiwania mogą zawieść Jak przekonałeś się na podstawie treści tego rozdziału, wyszukiwarki są w stanie wykonać bardzo złożone operacje. Zdarzają się jednak sytuacje, kiedy to cały proces nie działa tak jak powinien. Częściowo wynika to z faktu, iż użytkownicy wpisują zapytania, które mówią naprawdę niewiele o ich zamiarach (np. jeżeli wyszukują informacji o samochodzie, to czy interesuje ich zakup, chcą przeczytać recenzję produktu, nauczyć się prowadzić auto, nauczyć się je konstruować, czy jeszcze coś innego?). Innym powodem tego problemu jest wieloznaczność niektórych słów (np. słowo „jaguar” oznacza zwierzę, samochód lub markę gitary). Więcej o tym, dlaczego algorytmy wyszukiwania zawodzą, znajdziesz w napisanym przez Hamleta Batistę artykule pt. 7 Reasons Why Search Engines Don’t Return Relevant Results 100% of the Time.
 SEO, czyli sztuka optymalizacji witryn dla wyszukiwarek
SEO, czyli sztuka optymalizacji witryn dla wyszukiwarekWydawnictwo Helion 2016 Spis treści >> Przejdź do księgarni >>
Zobacz nasze propozycje
-

-
książka
-
ebook
(46,20 zł najniższa cena z 30 dni)
46.20 zł
77.00 zł (-40%) -
-

-
książka
-
ebook
(77,40 zł najniższa cena z 30 dni)
77.40 zł
129.00 zł (-40%) -
-

-
książka
-
ebook
(53,40 zł najniższa cena z 30 dni)
53.40 zł
89.00 zł (-40%) -
-
-
kurs
(149,25 zł najniższa cena z 30 dni)
39.90 zł
199.00 zł (-80%) -
-

-
książka
-
ebook
(47,40 zł najniższa cena z 30 dni)
47.40 zł
79.00 zł (-40%) -
-

-
książka
-
ebook
(52,20 zł najniższa cena z 30 dni)
52.20 zł
87.00 zł (-40%) -
-

-
książka
-
ebook
(35,94 zł najniższa cena z 30 dni)
35.94 zł
59.90 zł (-40%) -
-

-
książka
-
ebook
(38,94 zł najniższa cena z 30 dni)
38.94 zł
64.90 zł (-40%) -
-

-
książka
-
ebook
(59,40 zł najniższa cena z 30 dni)
59.40 zł
99.00 zł (-40%) -
-

-
książka
-
ebook
(53,40 zł najniższa cena z 30 dni)
53.40 zł
89.00 zł (-40%) -
-

-
książka
-
ebook
(53,40 zł najniższa cena z 30 dni)
53.40 zł
89.00 zł (-40%) -
-

-
kurs
(134,25 zł najniższa cena z 30 dni)
39.90 zł
179.00 zł (-78%) -
-

-
książka
-
ebook
(77,40 zł najniższa cena z 30 dni)
77.40 zł
129.00 zł (-40%) -
-

-
książka
-
ebook
-
audiobook
(29,94 zł najniższa cena z 30 dni)
29.94 zł
49.90 zł (-40%) -
-

-
książka
-
ebook
(47,40 zł najniższa cena z 30 dni)
47.40 zł
79.00 zł (-40%) -
-

-
książka
-
ebook
(59,40 zł najniższa cena z 30 dni)
59.40 zł
99.00 zł (-40%) -
-

-
książka
-
ebook
(34,50 zł najniższa cena z 30 dni)
41.40 zł
69.00 zł (-40%) -
-

-
książka
-
ebook
(119,40 zł najniższa cena z 30 dni)
119.40 zł
199.00 zł (-40%) -
-

-
książka
-
ebook
(59,40 zł najniższa cena z 30 dni)
59.40 zł
99.00 zł (-40%) -
-

-
książka
-
ebook
(71,40 zł najniższa cena z 30 dni)
71.40 zł
119.00 zł (-40%) -





