

Embeddingi w sztucznej inteligencji - co to takiego?
Spis treści
Modele głębokich sieci neuronowych, włącznie z modelami LLM, nie potrafią bezpośrednio przetwarzać surowego tekstu. Ponieważ tekst jest skategoryzowany, nie nadaje się do wykonywania działań matematycznych wykorzystywanych w procesach implementacji i szkolenia sieci neuronowych. Dlatego trzeba znaleźć sposób na reprezentowanie słów w postaci wektorów zawierających ciągłe wartości.
Czym są osadzenia słów?
Konwersję danych na format wektorowy często określa się jako osadzanie (ang. embedding). Korzystając z określonej warstwy sieci neuronowej lub innego wstępnie przeszkolonego modelu sieci neuronowej, można osadzać różne typy danych — na przykład wideo, audio i tekst. Należy jednak pamiętać, że różne formaty danych wymagają różnych modeli osadzeń. Na przykład model osadzania zaprojektowany pod kątem tekstu nie jest odpowiedni do osadzania danych audio lub wideo.
U podstaw osadzania leży mapowanie dyskretnych obiektów, takich jak słowa, obrazy, a nawet całe dokumenty, na punkty w ciągłej przestrzeni wektorowej — głównym celem osadzania jest konwersja danych nieliczbowych na format, który można przetwarzać w sieciach neuronowych.
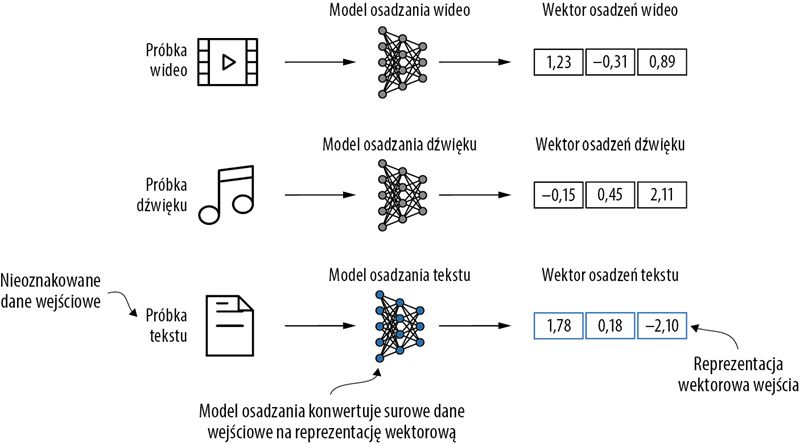
Modele uczenia głębokiego nie potrafią przetwarzać takich formatów danych jak wideo, audio i tekst w surowej postaci. Z tego powodu używamy modelu osadzania, którego zadaniem jest przekształcenie surowych danych w gęstą reprezentację wektorową, którą architektury uczenia głębokiego mogą łatwo zrozumieć i przetworzyć. W szczególności ten rysunek ilustruje proces przekształcania surowych danych w trójwymiarowy wektor liczbowy.
Podczas gdy osadzanie słów jest najbardziej powszechną formą osadzania tekstu, istnieją również osadzenia zdań, akapitów lub całych dokumentów. Osadzanie zdań lub akapitów jest popularną opcją stosowaną w przypadku techniki RAG (ang. retrieval augmented generation — dosłownie: generowanie wspomagane wyszukiwaniem). Technika RAG łączy generowanie (np. tworzenie tekstu) z wyszukiwaniem (np. przeszukiwaniem zewnętrznej bazy wiedzy) w celu uzyskania odpowiednich informacji w trakcie generowania tekstu.
Do generowania osadzeń słów opracowano kilka algorytmów i frameworków. Jednym z wcześniejszych i najpopularniejszych przykładów jest podejście Word2Vec. Word2Vec wykorzystuje architekturę sieci neuronowej do generowania osadzeń słów przez przewidywanie kontekstu danego słowa na podstawie słowa docelowego lub odwrotnie (słowa docelowego na podstawie jego kontekstu). Zgodnie z głównym założeniem Word2Vec słowa pojawiające się w podobnych kontekstach zwykle mają zbliżone znaczenie. W rezultacie, jak pokazano na następnym rysunku, po zrzutowaniu na dwuwymiarowe osadzenia słów do celów wizualizacji podobne terminy są pogrupowane.
Osadzenia słów mogą mieć różne wymiary — od jednego do wielu tysięcy. Wyższa wymiarowość pozwala uchwycić bardziej zniuansowane relacje, ale kosztem wydajności obliczeniowej.
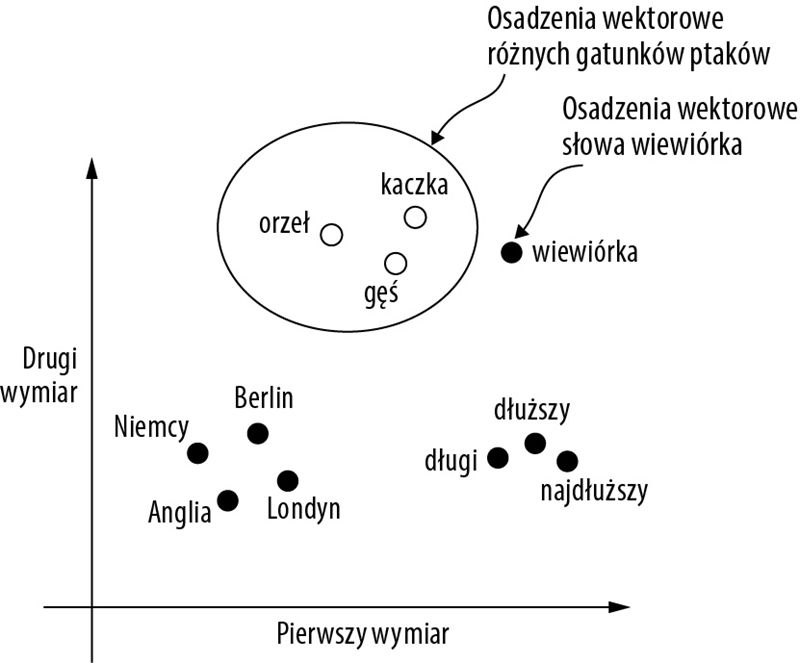
Jeśli osadzenia słów są dwuwymiarowe, można w celu wizualizacji wykreślić je na dwuwymiarowym wykresie punktowym tak, jak pokazano na rysunku. W przypadku korzystania z technik osadzania słów, takich jak Word2Vec, słowa odpowiadające podobnym pojęciom często pojawiają się w przestrzeni osadzania blisko siebie. Na przykład różne gatunki ptaków pojawiają się w przestrzeni osadzania bliżej siebie i w oddaleniu od krajów bądź miast.
Chociaż do generowania osadzeń na potrzeby modeli uczenia maszynowego można użyć wstępnie przeszkolonych modeli, takich jak Word2Vec, modele LLM zazwyczaj tworzą własne osadzenia, które są częścią warstwy wejściowej i są aktualizowane podczas uczenia. Zaletą optymalizacji osadzeń w ramach szkolenia LLM zamiast korzystania z Word2Vec jest uzyskanie osadzeń zoptymalizowanych pod kątem konkretnego zadania i dostępnych danych.
Niestety, wielowymiarowe osadzenia są trudne do zwizualizowania, ponieważ ludzka percepcja zmysłowa i typowe reprezentacje w formie grafu z natury są ograniczone do trzech lub mniejszej liczby wymiarów. Z tego powodu na powyższym rysunku przedstawiono dwuwymiarowe osadzenia na dwuwymiarowym wykresie punktowym. Podczas pracy z modelami LLM zazwyczaj jednak wykorzystuje się osadzenia o znacznie wyższej wymiarowości. Zarówno w przypadku GPT-2, jak i GPT-3 wymiar osadzeń (często określany jako wymiarowość ukrytych stanów modelu) różni się w zależności od konkretnego wariantu i rozmiaru modelu. Jest to kompromis między wydajnością a skutecznością. Dla przykładu, najmniejsze modele GPT-2 (117 mln i 125 mln parametrów) wykorzystują osadzenia o 768 wymiarach. Największy model GPT-3 (175 mld parametrów) wykorzystuje osadzenia o 12 288 wymiarach(!).
* Fragment pochodzi z książki "Stwórz własne AI. Jak od podstaw zbudować duży model językowy" - Sebastian Raschka, Helion 2025
Zobacz nasze propozycje
-

-
książka
-
ebook
(59,40 zł najniższa cena z 30 dni)
60.39 zł
99.00 zł (-39%) -





