


Debugowanie - zestaw porad dla koderów
Po ustabilizowaniu błędu i uściśleniu powodującego jego wystąpienie testu, znalezienie przyczyny może być trywialne lub wciąż bardzo trudne. Zależy to od jakości poprawianego kodu — jeżeli wyszukiwanie błędu jest kłopotliwe, przyczyną może być to, że jest on napisany źle. Może Ci się to nie podobać, ale tak jest. Gdy pojawiają się problemy ze znalezieniem przyczyny błędów, uwzględnij poniższe wskazówki.
Przy tworzeniu hipotez bierz pod uwagę wszystkie dostępne dane.
Gdy formułujesz hipotezę dotyczącą źródła defektu, wykorzystaj jak najwięcej danych. W rozważanym przykładzie mogłeś zauważyć, że Fruit-Loop, Frita jest w niewłaściwym miejscu, i stworzyć hipotezę, iż błędnie sortowane są nazwy zaczynające się od litery „F”. Nie jest ona dobra, bo nie uwzględnia tego, że również Modula, Mildred był w niewłaściwym miejscu, ani tego, że przy drugim uruchomieniu programu sortowanie było poprawne. Jeżeli dane nie pasują do hipotezy, nie odrzucaj ich — zastanów się, na czym polega ich niedopasowanie, i sformułuj nową hipotezę.
Druga hipoteza w przykładzie — że problem jest związany z nazwami zawierającymi znak łącznika, a nie wprowadzanymi pojedynczo — również początkowo nie uwzględniała tego, że nazwy za drugim razem były sortowane poprawnie.
W tym jednak przypadku doprowadziła ona do sformułowania bardziej dopracowanej hipotezy, która okazała się prawdziwa. Jest dopuszczalne, by hipoteza nie uwzględniała początkowo wszystkich danych, o ile zostaje potem uściślona w taki sposób, aby uzupełnić ten brak.
Uściślaj testy, które powodują wystąpienie błędu.
Jeżeli nie możesz znaleźć przyczyny błędu, próbuj dalszego doprecyzowywania testów. Może się okazać, że dany parametr można zmienić w dużo większym stopniu, niż początkowo zakładałeś, a koncentracja na jednym z parametrów może doprowadzić do przełomu.
Sprawdzaj kod w systemie testów jednostkowych.
Defekty łatwiej jest znaleźć w małych fragmentach kodu niż w całym dużym, zintegrowanym programie. Używaj testów jednostkowych, aby sprawdzać działanie kodu w izolacji od innych jego części.
Używaj dostępnych narzędzi.
Jest wiele narzędzi wspomagających debugowanie: interakcyjne debuggery, kompilatory dokładniej sprawdzające kod, narzędzia sprawdzające pamięć, edytory z kontrolą składni i inne. Właściwe narzędzie może znacznie uprościć skomplikowane zadanie. Jeden z trudnych do znalezienia błędów polegał na tym, że jedna część programu zapisywała pamięć innej. Było to trudne do zdiagnozowania przy użyciu konwencjonalnych metod debugowania, ponieważ nie można było wskazać konkretnego miejsca, w którym program wykonywał niewłaściwą operację zapisu do pamięci. Programista wykorzystał więc punkt kontrolny pamięci (ang. memory breakpoint), aby ustawić czujkę ukierunkowaną na określony adres. Gdy program wykonał operację zapisu we wskazanej lokalizacji, debugger zatrzymał wykonywanie i wadliwy kod został ujawniony.
Jest to przykład problemu trudnego do zdiagnozowania w sposób analityczny, ale całkiem prostego, gdy tylko programista znalazł właściwe narzędzie.
Replikuj błąd kilkoma sposobami.
Czasem pomocne jest wykonywanie testów podobnych w pewien sposób do wykrywającego błąd. Przypomina to metodę triangulacji. Po uzyskaniu kilku różnych „namiarów” łatwiej jest określić dokładne położenie.
Jak pokazuje Rysunek 23-1, doprowadzanie do wystąpienia błędu kilkoma różnymi metodami pomaga w diagnozowaniu jego przyczyny. Gdy wydaje Ci się, że zidentyfikowałeś defekt, uruchom test zbliżony do tych, które powodują błędy, ale zarazem taki, który sam nie powinien ich wywoływać. Jeżeli test ten doprowadzi jednak do wystąpienia błędu, oznacza to, że Twoja wiedza na temat rozwiązywanego problemu nie jest jeszcze wystarczająca. Błędy są często skutkiem połączenia pewnych czynników i próby diagnozowania oparte na pojedynczym teście nieraz nie prowadzą do znalezienia ich źródła.
Wygeneruj więcej danych, aby utworzyć więcej hipotez.
Wybierz testy inne niż te, o których już wiesz, że prowadzą do błędów lub nie. Uruchom je, aby wygenerować więcej danych, i użyj tych danych w formułowaniu hipotez.
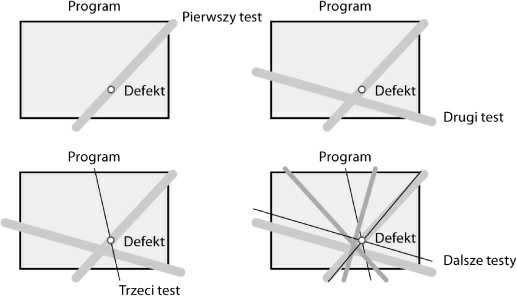 Rysunek 23-1. Aby dokładnie określić przyczynę błędu, spróbuj wywołać go na kilka sposobów
Używaj negatywnych wyników testów.
Powiedzmy, że formułujesz hipotezę, uruchamiasz test w celu jej weryfikacji i test ten prowadzi do jej odrzucenia. Wciąż nie znasz przyczyny błędu, ale wiesz już coś, czego nie wiedziałeś wcześniej — że defekt nie znajduje się tam, gdzie go oczekiwałeś. Zawęża to obszar poszukiwań i zmniejsza zbiór możliwych hipotez.
Próbuj burzy mózgów w poszukiwaniu hipotez.
Zamiast ograniczać się do pierwszej wymyślonej hipotezy, spróbuj sformułować kilka. Nie analizuj ich od razu. Po prostu postaraj się utworzyć ich jak najwięcej w ciągu kilku minut. Następnie przejrzyj uzyskaną listę hipotez i spróbuj dopasować testy, które potwierdzą lub obalą każdą z nich. To proste ćwiczenie umysłowe jest bardzo pomocne w przerywaniu patowych sytuacji, gdy nadmierne przywiązanie do jednego toku myślenia uniemożliwia znalezienie rozwiązania.
Miej pod ręką zeszyt i zapisuj rzeczy, których mógłbyś spróbować.
Jedną z rzeczy, które często utrudniają doprowadzenie sesji debugowania do szczęśliwego końca, jest nadmierne zapuszczanie się w różne „ślepe uliczki”. Twórz listę rozwiązań, których warto spróbować, i gdy jedna metoda nie działa, sprawnie przechodź do innej.
Zawężaj podejrzany obszar kodu.
Jeżeli testujesz cały program, całą klasę lub procedurę, przejdź do testowania mniejszej części. Używaj instrukcji print oraz rejestrowania i śledzenia wartości, aby określić, który fragment kodu odpowiada za błąd.
Jeżeli metody te nie wystarczają do zmniejszenia podejrzanego obszaru kodu, próbuj systematycznie usuwać części programu, sprawdzając, czy błąd wciąż występuje. Jeżeli przestaje się on pojawiać, oznacza to, że kłopotliwy fragment kodu jest w usuniętej części. Gdy błąd pojawia się dalej, problem dotyczy pozostawionego kodu.
Rysunek 23-1. Aby dokładnie określić przyczynę błędu, spróbuj wywołać go na kilka sposobów
Używaj negatywnych wyników testów.
Powiedzmy, że formułujesz hipotezę, uruchamiasz test w celu jej weryfikacji i test ten prowadzi do jej odrzucenia. Wciąż nie znasz przyczyny błędu, ale wiesz już coś, czego nie wiedziałeś wcześniej — że defekt nie znajduje się tam, gdzie go oczekiwałeś. Zawęża to obszar poszukiwań i zmniejsza zbiór możliwych hipotez.
Próbuj burzy mózgów w poszukiwaniu hipotez.
Zamiast ograniczać się do pierwszej wymyślonej hipotezy, spróbuj sformułować kilka. Nie analizuj ich od razu. Po prostu postaraj się utworzyć ich jak najwięcej w ciągu kilku minut. Następnie przejrzyj uzyskaną listę hipotez i spróbuj dopasować testy, które potwierdzą lub obalą każdą z nich. To proste ćwiczenie umysłowe jest bardzo pomocne w przerywaniu patowych sytuacji, gdy nadmierne przywiązanie do jednego toku myślenia uniemożliwia znalezienie rozwiązania.
Miej pod ręką zeszyt i zapisuj rzeczy, których mógłbyś spróbować.
Jedną z rzeczy, które często utrudniają doprowadzenie sesji debugowania do szczęśliwego końca, jest nadmierne zapuszczanie się w różne „ślepe uliczki”. Twórz listę rozwiązań, których warto spróbować, i gdy jedna metoda nie działa, sprawnie przechodź do innej.
Zawężaj podejrzany obszar kodu.
Jeżeli testujesz cały program, całą klasę lub procedurę, przejdź do testowania mniejszej części. Używaj instrukcji print oraz rejestrowania i śledzenia wartości, aby określić, który fragment kodu odpowiada za błąd.
Jeżeli metody te nie wystarczają do zmniejszenia podejrzanego obszaru kodu, próbuj systematycznie usuwać części programu, sprawdzając, czy błąd wciąż występuje. Jeżeli przestaje się on pojawiać, oznacza to, że kłopotliwy fragment kodu jest w usuniętej części. Gdy błąd pojawia się dalej, problem dotyczy pozostawionego kodu.
Nie usuwaj części kodu chaotycznie. Posłuż się algorytmem wyszukiwania binarnego. Rozpocznij od usunięcia połowy kodu. Ustal, w której połowie jest defekt, i podziel tę część znowu. Ponownie określ miejsce defektu i kolejny raz podziel wadliwy fragment na pół. Powtarzaj ten proces aż do znalezienia defektu.
Jeżeli korzystasz z wielu małych procedur, najprostszą metodą usuwania części kodu może być oznaczanie ich wywołań znakami komentarza. W innych przypadkach możesz w podobny sposób dezaktywować wybrane instrukcje lub sekwencje instrukcji. Alternatywą dla stosowania znaków komentarza mogą być polecenia preprocesora.
Jeżeli stosujesz debugger, usuwanie części kodu może nie być konieczne. Możesz ustawić punkt kontrolny (przerwania) w pewnym miejscu programu i wykorzystać go do wyszukiwania defektu. Jeżeli debugger pozwala pomijać wywołania procedur, wyeliminuj część z nich, korzystając z tej możliwości i sprawdzając, czy błąd dalej występuje. Pozwala to uzyskać efekt nieróżniący się w istotny sposób od fizycznego usunięcia fragmentów kodu.
Zwracaj szczególną uwagę na klasy i procedury, w których wcześniej występowały błędy.
Klasy, które miały wcześniej defekty, to klasy, w których prawdopodobieństwo wystąpienia kolejnych błędów jest największe. Gdy szukasz źródła problemów, zwracaj na nie szczególną uwagę.
Sprawdzaj ostatnio zmieniany kod.
Jeżeli masz do czynienia z trudnym do zdiagnozowania błędem, jest to zazwyczaj związane z niedawno wprowadzonymi zmianami. Może to dotyczyć kodu zupełnie nowego lub zmian w starszych procedurach i klasach. Jeżeli nie możesz znaleźć defektu, uruchom starą wersję programu i sprawdź, czy w niej też występuje błąd. Jeżeli nie, wiesz, że problem dotyczy nowej wersji lub jest spowodowany przez interakcje z nią. Ustal dokładnie, jakie są różnice między starą wersją a nową. Sprawdź dziennik systemu kontroli wersji, aby dowiedzieć się, jakie były ostatnie zmiany. Jeżeli nie ma takiej możliwości, użyj narzędzia typu diff, aby porównać stary, działający kod z nowym.
Zwiększaj podejrzany obszar kodu.
Łatwo skupić uwagę na niewielkim fragmencie kodu w przekonaniu, że „błąd musi być w tej części”. Jeżeli jednak nie można go znaleźć, rozważ możliwość, że defekt jest gdzie indziej. Poszerz obszar poszukiwań i zastosuj opisywaną wcześniej metodę wyszukiwania binarnego.
Integruj przyrostowo.
Debugowanie jest łatwe, gdy dodajesz elementy do systemu pojedynczo. Jeżeli po dodaniu nowego komponentu pojawia się nowy błąd, usuń ten komponent i sprawdź jego pracę osobno.
Wyszukuj typowe defekty.
Użyj list kontrolnych jakości kodu jako pomocy ułatwiającej zwrócenie uwagi na elementy, które mogłeś przeoczyć.
Porozmawiaj o problemie.
Niektórzy nazywają to „debugowaniem zwierzeniowym”. Często samo opisanie sytuacji innej osobie okazuje się skuteczną drogą do odkrycia defektu. W przypadku rozważanego przykładu z bazą danych pracowników mogłoby to wyglądać tak:
Hej, Jenny, masz chwilę? Mam tu problem... Mam tę listę podatków za pracowników, która powinna być posortowana, ale niektóre nazwiska wychodzą w niewłaściwej kolejności. Gdy próbuję drugi raz, wszystko jest w porządku, ale za pierwszym razem nie. Sprawdzałem, czy chodzi o nowo wprowadzane rekordy, ale było kilka takich, które działały OK. Wiem, że wszystkie powinny być już za pierwszym razem posortowane, bo program sortuje nazwy od razu po ich wprowadzeniu, a potem jeszcze przy zapisywaniu — moment — nie, sortowanie przy wpisywaniu nie działa. Racja. To jest tylko porządkowanie „z grubsza”. Dzięki, Jenny. Baaardzo mi pomogłaś.
Jennifer nie powiedziała ani słowa, a Ty znalazłeś swoje rozwiązanie. Nie ma w tym nic nadzwyczajnego — jest to metoda o ogromnym potencjale w rozwiązywaniu trudnych problemów.
Zrób sobie przerwę.
Czasem koncentrujesz się na problemie tak mocno, że nie jesteś w stanie wymyślić nic nowego. Ile już razy robiłeś sobie przerwę na kawę i w drodze do ekspresu znajdowałeś poszukiwane rozwiązanie? Ile razy zdarzyło się to w środku lunchu? Ile razy w drodze do domu lub pod prysznicem następnego dnia? Jeżeli wielogodzinne debugowanie nie przynosi efektu i masz wrażenie, że spróbowałeś już wszystkiego, odłóż problem na później. Pójdź na spacer. Popracuj nad czymś innym. Wyjdź wcześniej z pracy. Daj szansę swojej podświadomości.
Dodatkową korzyścią z odłożenia problemu na potem jest zmniejszenie napięcia związanego z debugowaniem. Gdy stajesz się nerwowy, jest to wyraźna wskazówka, że czas zrobić przerwę.
Debugowanie „brute force”
Metoda „brute force” jako technika debugowania jest często niedoceniana. Mam tu na myśli metodę, która może być nużąca i czasochłonna, ale gwarantuje znalezienie rozwiązania. To, która konkretnie technika do niego doprowadzi, zależy od kontekstu, ale można wskazać kilka typowych możliwości:
- przeprowadzenie pełnego przeglądu projektu i (lub) kodu, który sprawia problemy;
- wyrzucenie części kodu i zaprojektowanie (napisanie) go od nowa;
- wyrzucenie całego programu i zaprojektowanie (napisanie) go od początku;
- skompilowanie kodu z opcją wyświetlania wszystkich informacji wspomagających debugowanie;
- skompilowanie kodu z opcją wyświetlania wszystkich ostrzeżeń i doprowadzenie do ich całkowitego wyeliminowania;
- testowanie nowego kodu w całkowitej izolacji od innych części;
- utworzenie zautomatyzowanego pakietu testów, który będzie pracował przez całą noc;
- krokowe wykonywanie dużej pętli w debuggerze aż do wystąpienia błędu;
- dodawanie do kodu kolejnych instrukcji print i innych instrukcji rejestrujących;
- skompilowanie kodu innym kompilatorem;
- skompilowanie i uruchomienie kodu w innym środowisku;
- linkowanie i uruchamianie kodu ze specjalnymi bibliotekami lub środowiskami wykonawczymi, które generują ostrzeżenia, gdy użycie kodu jest niewłaściwe;
- replikacja pełnej konfiguracji komputera użytkownika;
- integrowanie nowego kodu w małych częściach z pełnym testowaniem każdego wprowadzonego elementu.
Określ limit czasu dla szybkiego debugowania.
Twoją reakcją na metodę „brute force” może być stwierdzenie: „Tego nie mogę robić — nie mam na to czasu!”. Sęk w tym, że taki argument utrzymuje swoją wagę, tylko jeśli metoda „brute force” wymaga czasu dłuższego niż „szybkie debugowanie”. Zawsze kusząca będzie myśl o sprawnym odgadnięciu przyczyny problemu. Wydaje się to dużo ciekawszą perspektywą niż systematyczne dodawanie i usuwanie elementów kodu do momentu, gdy defekt nie ma już żadnej niesprawdzonej kryjówki. W każdym znajdzie się coś z hazardzisty, który podejmie ryzykowną próbę znalezienia defektu w pięć minut, jeżeli alternatywą jest pewna i systematyczna metoda trwająca pół godziny. Problem polega na tym, że gdy szybka metoda zawodzi, pojawia się upór. Znalezienie defektu „szybko i sprawnie” staje się priorytetem i mijają godziny, a potem dni, tygodnie, miesiące... Ile razy poświęciłeś dwie godziny na debugowanie kodu napisanego w 30 minut? Nie jest to dobry podział pracy — napisanie od podstaw nowego programu dałoby lepszy efekt niż mozolne debugowanie kodu z błędami.
Gdy decydujesz się na blitzkrieg, ustal limit czasowy. Gdy czas minie, pogódź się z faktem, że defekt jest trudniejszy do zdiagnozowania, niż początkowo myślałeś, i zajmij się nim w sposób systematyczny. Takie podejście zapewni, że proste defekty zostaną usunięte szybko, a trudniejsze — również w miarę sprawnie.
Zrób listę metod „brute force”.
Zanim rozpoczniesz debugowanie trudnego błędu, zadaj sobie pytanie: „Gdy nie będę mógł znaleźć rozwiązania, czy istnieje metoda, która gwarantuje jego znalezienie?”. Jeżeli zidentyfikujesz co najmniej jedną technikę „brute force”, która rozwiąże problem — włącznie z napisaniem kodu od nowa — samo istnienie takiej alternatywy zmniejszy prawdopodobieństwo, że stracisz godziny i dni na bezskutecznych wysiłkach.
Błędy składniowe
Problem błędów składniowych można już niemalże postawić w jednym rzędzie z mamutem i tygrysem szablozębnym. Kompilatory wyświetlają coraz lepsze komunikaty diagnostyczne i czasy wielogodzinnych poszukiwań brakującego średnika odchodzą w przeszłość. Oto lista zasad, których stosowanie przyspieszy wymarcie tego zagrożonego gatunku:
Nie ufaj numerom wierszy w komunikatach kompilatora.
Gdy kompilator zgłasza tajemniczy błąd składniowy, patrz na kod bezpośrednio przed i po wskazanym wierszu — kompilator może źle zrozumieć problem albo po prostu nie być do końca dopracowany. Po znalezieniu prawdziwego defektu spróbuj ustalić, dlaczego kompilator powiązał komunikat z niewłaściwą instrukcją. Zdobyta wiedza będzie pomocna przy szukaniu błędów w przyszłości.
Nie ufaj komunikatom kompilatora.
Kompilatory starają się dokładnie opisać, na czym polega problem, ale bywają zwodnicze, a czasem nawet bezczelnie wprowadzają w błąd i tylko czytanie między wierszami może uratować programistę przed niepotrzebną stratą czasu. W języku C systemu UNIX można spotkać się z komunikatem o błędzie operacji zmiennoprzecinkowej, gdy następuje próba dzielenia całkowitego przez zero. Pracując ze standardową biblioteką STL języka C++, można napotkać parę komunikatów: pierwszy opisuje prawdziwy błąd w korzystaniu z biblioteki; drugi jest generowany przez kompilator i mówi, że komunikat jest za długi dla drukarki i został obcięty. Prawdopodobnie sam też znasz kilka takich przykładów.
Nie ufaj drugiemu komunikatowi kompilatora.
Gdy w programie występuje więcej niż jeden błąd, niektóre kompilatory radzą sobie całkiem dobrze, a inne gorzej. Część z nich tak rozpływa się w zachwycie nad swoją skutecznością, że przy analizie dalszego kodu zupełnie tracą zdrowy rozsądek. Wyświetlają dziesiątki komunikatów, które mają niewiele wspólnego z rzeczywistością. Inne kompilatory zachowują się w sposób bardziej zrównoważony i po znalezieniu pierwszego błędu nie wyrzucają z siebie strumienia bezwartościowej treści. Jeżeli Twój kompilator generuje serię wstrząsających komunikatów, nie szukaj przyczyny drugiego, trzeciego i dalszych. Usuń powód pojawienia się pierwszego i skompiluj program ponownie.
Dziel i rządź. Metoda dzielenia programu na części w celu znalezienia defektów jest szczególnie skuteczna w przypadku błędów składniowych. Gdy masz do czynienia z kłopotliwym defektem tego rodzaju, usuń część kodu i skompiluj program ponownie. Mogą wtedy wystąpić trzy sytuacje: brak błędu (bo był w usuniętej części), ten sam błąd (trzeba usunąć inną część) lub inny defekt (bo skłoniłeś kompilator do wyświetlenia sensowniejszego komunikatu).
Wyszukuj błędne znaki komentarza i cudzysłowy.
Wiele edytorów dla programistów automatycznie formatuje komentarze, ciągi znakowe i inne elementy składni. W środowiskach mniej rozwiniętych błędny komentarz lub cudzysłów może zdezorientować kompilator. Aby wyszukać niepotrzebny znak cudzysłowu lub komentarza, możesz wstawić w kodzie w języku C, C++ lub Java, następujący ciąg znaków:
/*"/**/
Jest to sekwencja, która zamyka komentarz albo ciąg. Pomaga to zawęzić obszar, w którym ukrywa się komentarz lub ciąg znaków bez odpowiedniego zakończenia.
 Tekst pochodzi z książki "Kod doskonały. Jak tworzyć oprogramowanie pozbawione błędów. Wydanie II" Steve'a McConnella (Wyd. Helion 2017).Sprawdź książkę >>Sprawdź eBook >>
Tekst pochodzi z książki "Kod doskonały. Jak tworzyć oprogramowanie pozbawione błędów. Wydanie II" Steve'a McConnella (Wyd. Helion 2017).Sprawdź książkę >>Sprawdź eBook >>
Zobacz nasze propozycje
-

- Druk
- PDF + ePub + Mobi
(44,94 zł najniższa cena z 30 dni)
44.94 zł
74.90 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(38,94 zł najniższa cena z 30 dni)
35.94 zł
59.90 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(38,94 zł najniższa cena z 30 dni)
35.94 zł
59.90 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(59,40 zł najniższa cena z 30 dni)
59.40 zł
99.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(57,84 zł najniższa cena z 30 dni)
53.40 zł
89.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(35,40 zł najniższa cena z 30 dni)
35.40 zł
59.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
- Audiobook MP3
(20,94 zł najniższa cena z 30 dni)
20.94 zł
34.90 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(53,40 zł najniższa cena z 30 dni)
53.40 zł
89.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(40,20 zł najniższa cena z 30 dni)
40.20 zł
67.00 zł (-40%) -

- Druk
(77,40 zł najniższa cena z 30 dni)
77.40 zł
129.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(32,94 zł najniższa cena z 30 dni)
32.94 zł
54.90 zł (-40%) -

- Druk
- PDF + ePub + Mobi
Programowanie wspomagane sztuczną inteligencją. Lepsze planowanie, kodowanie, testowanie i wdrażanie
(47,40 zł najniższa cena z 30 dni)
47.40 zł
79.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(47,40 zł najniższa cena z 30 dni)
47.40 zł
79.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(43,55 zł najniższa cena z 30 dni)
40.20 zł
67.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
- Audiobook MP3
(29,94 zł najniższa cena z 30 dni)
29.94 zł
49.90 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(53,40 zł najniższa cena z 30 dni)
53.40 zł
89.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(29,40 zł najniższa cena z 30 dni)
29.40 zł
49.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(47,40 zł najniższa cena z 30 dni)
47.40 zł
79.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(47,40 zł najniższa cena z 30 dni)
47.40 zł
79.00 zł (-40%) -

- Druk
- PDF + ePub + Mobi
(101,40 zł najniższa cena z 30 dni)
101.40 zł
169.00 zł (-40%)





